

Accelerating Inference With Prompt Compression
The inference process is one of the things that greatly increases the money and time costs of using large language models. This problem augments considerably for longer inputs. Below, you can see the relationship between model performance and inference time.
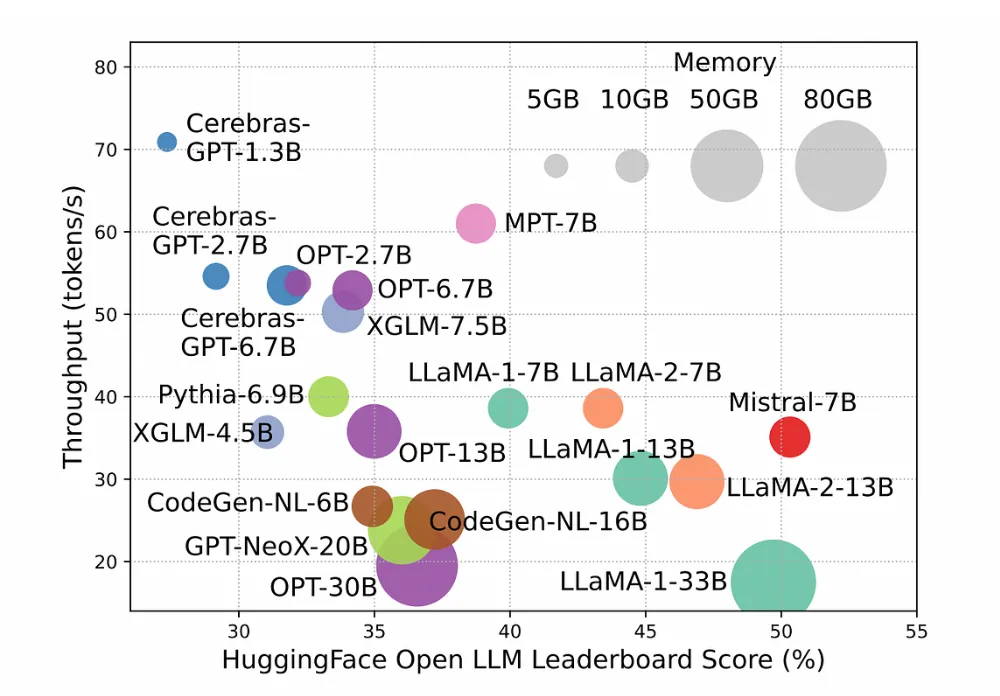
High-speed models, which produce more tokens each second, generally achieve lower rankings on the Open LLM Leaderboard. Increasing the size of the model leads to improved functionality but results in diminished processing capacity. This presents challenges for their implementation in practical scenarios [1].
Boosting the speed of LLMs and cutting down on their resource demands would make them accessible to more people and smaller entities.
Various strategies have been suggested to boost the efficiency of LLMs; some concentrate on modifying the model’s structure or its operational system. Yet, access to proprietary models such as ChatGPT or Claude is restricted to API use, preventing alterations to their core algorithm.
We will explore a straightforward and cost-effective technique that depends solely on modifying the input to the model — prompt condensation.
To begin, it’s essential to understand how LLMs process language. The initial step in comprehending natural language text involves breaking it down into segments. This procedure is known as tokenization. A token might be a complete word, part of a word, or a string of characters often found in contemporary dialogue.

Example of tokenization. Image by author.
As a rule of thumb, the number of tokens is 33% higher than the number of words. So, 1000 words correspond to approximately 1333 tokens.
Let’s look specifically at the OpenAI pricing for the gpt-3.5-turbo model, as it’s the model we will use down the line.

The inference procedure incurs expenses for both the input tokens, which represent the prompt provided to the model, and the output tokens, which are the text produced by the model.
Retrieval-Augmented Generation is one of the use cases where the input tokens are the most resource-intensive. The input may extend to thousands of tokens. In RAG, the user’s question is forwarded to a vector database, where the closest piece of data is identified and forwarded to the Large Language Model alongside the question. Within the vector database, it’s possible to incorporate personal documents that the model did not encounter during its primary training phase.
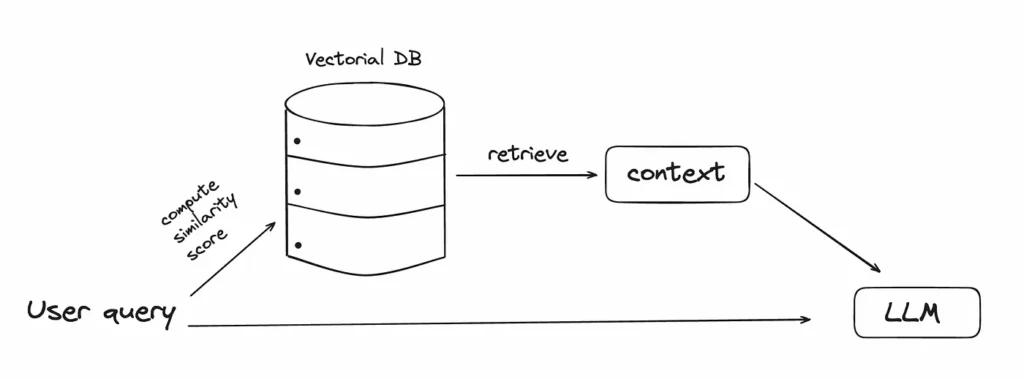
The number of tokens sent to the LLM can be significant depending on how many chunks of text are retrieved from the database.
Prompt Compression
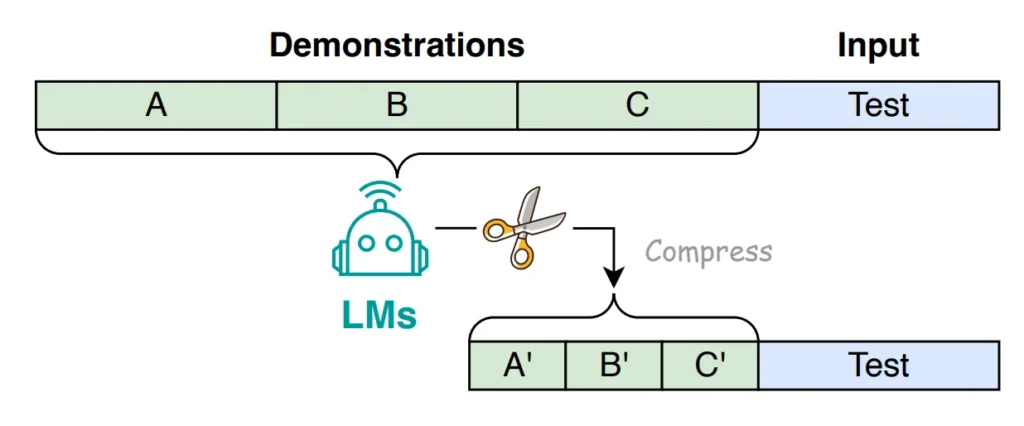
Prompt compression shortens the initial prompt while preserving the most crucial information. It also accelerates the speed at which the language model can process the inputs to assist it in generating rapid and precise responses.
This technique utilizes the fact that language frequently contains unnecessary repetition. Studies indicate English possesses a significant amount of redundancy — approximately 75% — in texts that are paragraph or chapter length [2]. This implies most of the words can be inferred from the words preceding them in the context.
Auto compressors
The inaugural technique we’ll examine is AutoCompressors. This method encapsulates lengthy texts into compact vector summaries, termed summary vectors. These condensed summary vectors subsequently serve as soft cues for the model [4].
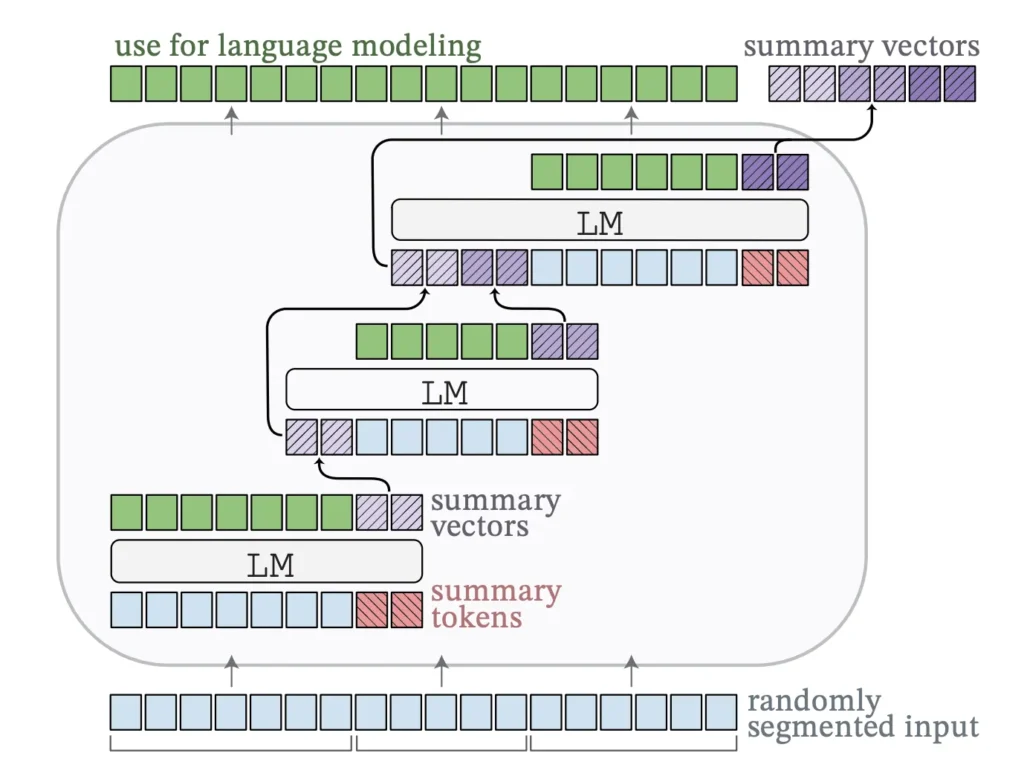
In the context of soft cues, the base model remains unaltered, while a minimal set of modifiable tokens is introduced at the start of the input text for every distinct task. These tokens are adaptable and are refined through training. They are fine-tuned in an integrated manner within the full model’s framework to ideally adapt to the particular task.
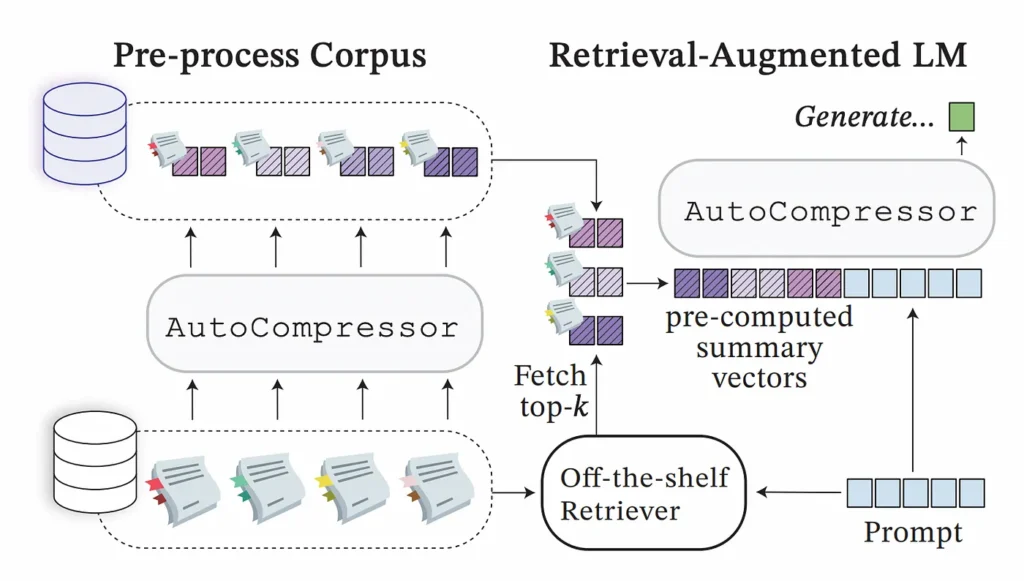
Regarding RAG, the catalogued documents might undergo preprocessing to convert into summary vectors. In the stage of retrieval, the selected segments are merged and dispatched to the LLM. The merging implies that their vector representations are concatenated sequentially to generate a unified, elongated vector. Essentially, these vectors are layered one atop the other.
To generate these summary vectors, the option exists to either develop a compressor independently or utilize an already developed one. Following is an illustration of employing the API with an already developed compressor, as showcased on the GitHub repository of the document
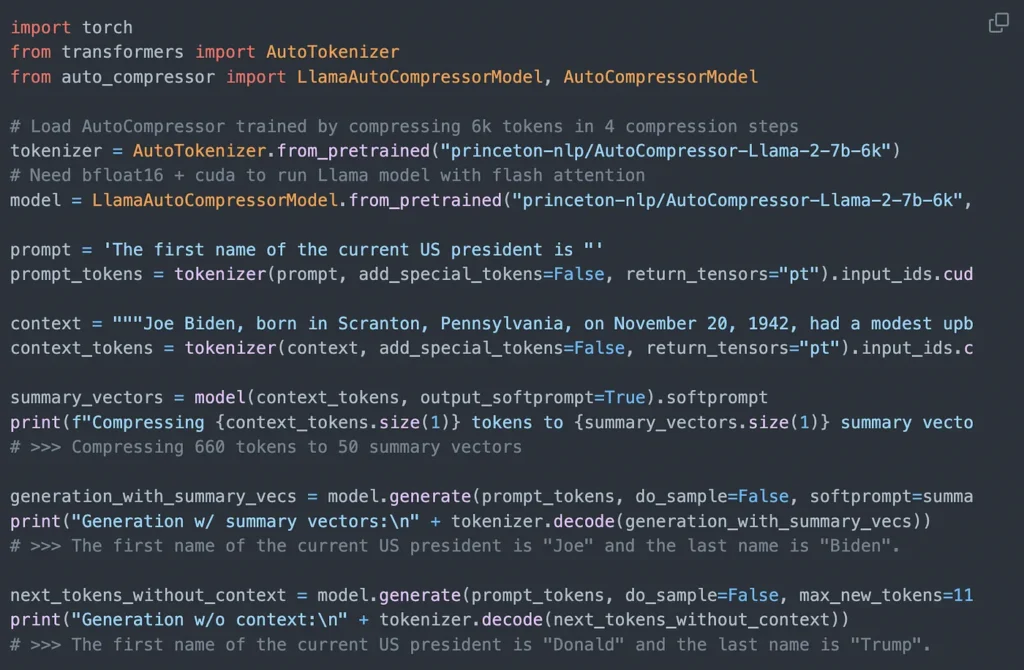
AutoCompressor-Llama-2–7b-6k is a fine-tuned version of the LLama-2–7B model.
Selective Context

In the realm of information theory, entropy quantifies the level of unpredictability or uncertainty in a piece of data. Within the scope of language models, it denotes the degree of uncertainty in forecasting the subsequent token in a sequence. An elevated entropy signifies a higher unpredictability.
When a language model like LLM makes token predictions with high confidence, these tokens contribute less to the overall entropy of the model. This led to the development of a technique for prompt condensation by excluding tokens that are highly predictable from the dataset.
The rationale is that omitting tokens with low perplexity has a negligible effect on the language model’s grasp of the context, as these tokens introduce little to no new information. Tokens with high perplexity are considered to possess high self-information values.
For the purpose of prompt reduction, a foundational language model such as Llama or GPT-2 calculates a self-information value for each lexical element (essentially measuring its surprise upon encountering it). A lexical element might be a phrase, sentence, or token, depending on our selection. Subsequently, the foundational model arranges the elements in a descending order based on their values and preserves only those in the top p-th percentile, with p being an adjustable parameter. The proponents of this method opted for a percentile-based strategy over a fixed-value approach for its adaptability.
Let us examine an instance of text compression utilizing different lexical elements.

Between these three lexical units, sentence-level compression keeps the original sentences intact. Also, a lower reduce ratio compresses the text more.
LongLLMLingua
Framework of LongLLMLingua [7]

The final method of compression we will discuss is LongLLMLingua. LongLLMLingua builds upon LLMLingua, which employs a foundational LLM like Llama to evaluate the perplexity of every token in a prompt, eliminating those with lower perplexities. This technique is rooted in information entropy, akin to Selective Context.
However, rather than merely excluding the tokens outright, LLMLingua utilizes a budget controller, a token-level prompt compression technique, and a mechanism for alignment of distribution. We will not delve deeply into these aspects, but further information can be found in the original paper [8].
The limitation of LLMLingua lies in its neglect to consider the user’s query during the compression phase, potentially leading to the preservation of non-relevant information. LongLLMLingua addresses this flaw by integrating the user’s inquiry into the compression procedure.
The four innovative components introduced are a question-sensitive coarse-to-fine compression method, a mechanism for document reordering, compression ratios, and a strategy for recovery of subsequences post-compression to enhance the perception of critical information by LLMs.
Question-Sensitive Coarse-Grained Compression signifies that rather than evaluating each document in isolation, the novel method examines the relationship of each document to the question. If a document renders the question appear more predictable or “less astonishing” to the model, it is considered more crucial.
Question-Aware Fine-Grained Compression
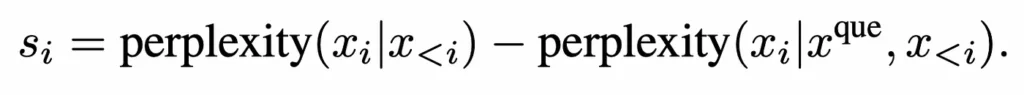
Contrastive perplexity equation [7]
Initially, we assess the usual level of surprise for a word (disregarding the question). The goal is to determine how the inclusion of the question alters the word’s level of surprise. If the presence of the question significantly reduces the surprise level of a word, it likely has high relevance to the question. Subsequently, we rearrange the documents in ascending order based on their relevance scores from the initial step. Thus, the documents with the highest relevance appear at the forefront.
Example of Recovering Subsequences: the original text is marked in red, while the outcome post-application of the LLaMA 2–7B tokenizer [7] is highlighted in blue. Compression might lead to the modification of critical entities such as dates or names, e.g., “2009” could be changed to “209,” or “Wilhelm Conrad Röntgen” might be altered to “Wilhelmgen.” To circumvent this issue, we initially pinpoint the longest substring within the LLM’s reply that coincides with a segment of the compressed prompt. This identified substring is deemed a crucial entity. Subsequently, we locate the unaltered, uncompressed subsequence corresponding to the compressed entity. Following this, we substitute the compressed entity with its original version.
RAG utilizing LlamaIndex and prompt compression will be demonstrated through the utilization of Nicolas Cage’s Wikipedia page. Given that the model likely encountered information regarding the actor during its training, we clarify that responses should be based solely on the fetched context. The Wikipedia page is accessed via the WikipediaReader() loader.
from llama_index import (
VectorStoreIndex,
download_loader,
load_index_from_storage,
StorageContext,
)
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
documents = loader.load_data(pages=['Nicolas Cage'])Now, we are building a simple vector store index. It takes only one line to do the chunking, embedding, and indexing of the documents.
The retriever will be used to return the most relevant documents given the user query. It does so by computing the similarity between the query and various document chunks within the embedding space. We want to retrieve the top 2 most similar chunks.
index = VectorStoreIndex.from_documents(documents)
<pre><code>retriever = index.as_retriever(similarity_top_k=2)</code></pre>Now that our data is stored in the index, we launch a user query. The retriever.retrieve(question) function searches the index to find the 2 chunks of data that are most similar to the query.
question = "Where did Nicolas Cage go to school?"
<pre><code>contexts = retriever.retrieve(question)
# Expected answer: Beverly Hills High School</code></pre>The contexts list carries NodeWithScore data entities with metadata and relationship information with other nodes. For now, we are only interested in the content.
context_list = [n.get_content() for n in contexts]
context_listThis is the retrieved context. Even if we choose to get only the top two documents, we still have to deal with a lot of text.
Retrieved text based on user query. Image by author.
We combine these relevant chunks with the original query to create a prompt. We will use a prompt template instead of just a f-string because we want to reuse it down the line.
We then feed this prompt into gpt-3.5-turbo-16k to generate a response.
# The response from original prompt
from llama_index.llms import OpenAI
from llama_index.prompts import PromptTemplate
<pre><code>llm = OpenAI(model="gpt-3.5-turbo-16k")
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
)
qa_template = PromptTemplate(template)
# you can create text prompt (for completion API)
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
response = llm.complete(prompt)
print(str(response))</code></pre>Output:
Nicolas Cage attended Beverly Hills High School and later attended UCLA School of Theater, Film and Television.
Now, let’s measure the RAG performance after using different prompt compression techniques.
Selective Context
We will use a reduce_ratio of 0.5 and see how the model does. If the compression keeps the information we are interested in, we will lower the value in order to compress more text.
from selective_context import SelectiveContext
sc = SelectiveContext(model_type='gpt2', lang='en')
context_string = "\n\n".join(context_list)
context, reduced_content = sc(context_string, reduce_ratio = 0.5,reduce_level="sent")
prompt = qa_template.format(context_str="\n\n".join(reduced_content), query_str=question)
response = llm.complete(prompt)
print(str(response))This is the reduced content.
Reduced content using selective context. Image by author.
It was compressed at the sentence level, but unfortunately, the information about where Nicolas Cage went to school got lost. We also tried token and phrase-level compression, but the information was still absent.
Output:
The provided information does not mention where Nicolas Cage went to school.
LongLLMLingua
# Setup LLMLingua
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder,
"dynamic_context_compression_ratio": 0.3,
},
)
retrieved_nodes = retriever.retrieve(question)
synthesizer = CompactAndRefine()The postprocess_nodes function is the one we care about the most because it shortens the node text given the query.
from llama_index.indices.query.schema import QueryBundle
<pre><code>new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=question)
)</code></pre>Now let’s see the results.
original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes])
compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes])
original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts)
compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
print(compressed_contexts)
print()
print("Original Tokens:", original_tokens)
print("Compressed Tokens:", compressed_tokens)
print("Compressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")Original Tokens: 2362 Compressed Tokens: 344 Compressed Ratio: 6.87x
Compressed context:
Compressed context using LLMLingua. Image by author.
Let’s see if the model understands the compressed context.
response = synthesizer.synthesize(question, new_retrieved_nodes)
print(str(response))Output:
Nicolas Cage attended Beverly Hills High School.
From the context compressed using longllmlingua , it is clear where the actor went to school. We also got almost a 7x reduction of input tokens! This translates to saving $0.00202. Imagine the cost reduction for 1B tokens. Normally, they would cost $1000, but with prompt compression, we’re just paying around $150.