
If you perceive your Apple MacBook solely as a device for creating PowerPoint presentations, surfing the internet, and watching series, then you truly misunderstand its capabilities.
Indeed, the MacBook transcends mere aesthetics; its prowess in artificial intelligence is equally astounding. Within the MacBook lies an impressively capable GPU, designed specifically to excel in the execution of AI algorithms.
The latest 2.8 version of AirLLM now enables a standard 8GB MacBook to operate cutting-edge 70B (billion parameter) AI models! This feat is accomplished without resorting to techniques like quantization, pruning, or model distillation for compression.
Our aim is to democratize AI by enabling the operation of elite models, which formerly necessitated eight A100 GPUs, on ordinary hardware.
A 70B model, solely with its model files, occupies in excess of 100GB. How does a typical MacBook with 8GB of RAM manage to run it? What sort of extraordinary computational power is concealed within a MacBook? Today, we’ll elucidate this.
MacBook’s Proficiency in AI
Apple indeed holds significant potential as a contender in the AI arena. iPhones and MacBooks already integrate numerous AI algorithms for tasks like computational photography, facial recognition, and video enhancement.
The operation of AI algorithms in real-time on mobile phones and laptops requires robust performance. Consequently, Apple consistently advances and refines its proprietary GPU chips.
The underlying operations for computational photography and video enhancement are fundamentally akin to those of large language models, mainly comprising various operations like additions, subtractions, multiplications, and divisions on extensive matrices. Hence, Apple’s self-designed GPU chips are well-positioned to compete in the age of generative AI.
The M1, M2, M3 series of Apple’s GPUs are indeed highly suitable platforms for AI computation.
Consider the following data:

Comparison of GFLOPS between the H100 and Apple M2 Ultra GPUs
A crucial measure of GPU efficiency is FLOPS (Floating-point Operations Per Second), which gauges the quantity of floating-point calculations performed per time unit. Apple’s most potent M2 Ultra GPU is still outperformed by Nvidia.
However, Apple’s edge is its memory. The training and inference phases of substantial language models frequently confront memory-related challenges. Running out of memory (OOM) is a significant issue for extensive language models. Apple’s GPUs and CPUs have the capability to share memory space, facilitating more expansive memory allocation. The memory capacity of the M2 Ultra GPU can extend up to 192GB, significantly surpassing the Nvidia H100’s peak of 80GB.
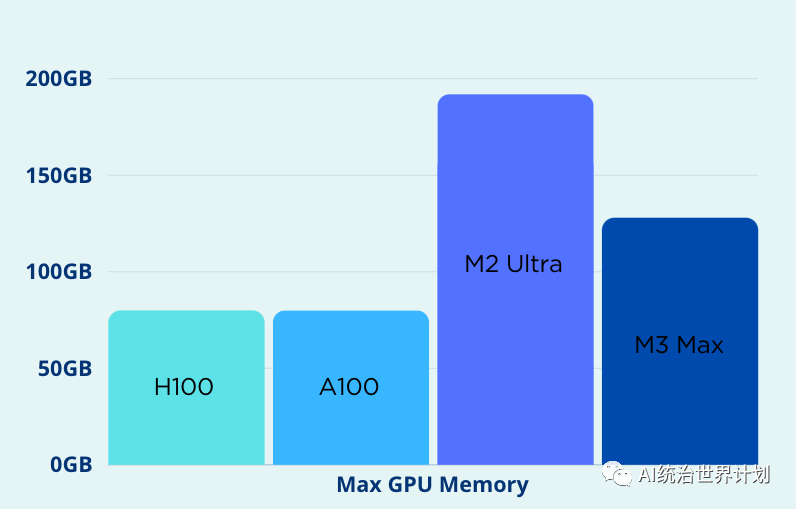
Comparison of Maximum GPU Memory
Nvidia is limited to optimizing the GPU architecture alone; it lacks influence over the CPU. Conversely, Apple has the liberty to uniformly optimize the GPU, CPU, memory, storage, etc. For example, Apple’s unified memory architecture permits genuine memory sharing between the GPU and CPU. This obviates the need for transferring data between CPU and GPU memory, eliminating the necessity for various zero-copy optimization strategies and achieving peak performance.
MLX Framework
Apple has introduced the open-source deep learning framework MLX.
MLX bears a strong resemblance to PyTorch. Its programming interface and syntax closely mirror those of Torch, making it straightforward for those acquainted with PyTorch to switch to the MLX framework.
Thanks to its hardware architecture’s advantages, MLX inherently supports unified memory. Tensors within memory are concurrently accessible by both GPU and CPU, negating the need for data migration and thus alleviating much additional workload.
Although MLX may not boast as extensive a feature set as PyTorch, its simplicity, directness, and clarity appeal to me. Possibly due to the absence of legacy compatibility obligations that burden PyTorch, MLX can be more nimble, allowing for more effective performance trade-offs and optimizations.
AirLLM for Mac
The recent AirLLM update has incorporated support based on the XLM platform. Its implementation mirrors that of the PyTorch version.

Transformer Architecture’s 80 Layers
As illustrated above, the substantial size and memory consumption of large language models are primarily due to their architecture, which includes numerous “layers.” A model with 70B parameters might contain as many as 80 layers. However, during inference, each layer operates independently, relying solely on the output from the preceding layer.
Thus, once a layer’s computation is complete, its memory can be freed, retaining only the output of that layer. Leveraging this principle, AirLLM has devised layered inference.
For an in-depth discussion, refer to our earlier publication: here.
Utilizing AirLLM is remarkably straightforward, necessitating only a handful of code lines:
AirLLM is entirely open-source and accessible on GitHub Repository