

In the past year, MultiModal Large Language Models (MM-LLMs) have undergone substantial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs via cost-effective training strategies. The resulting models not only preserve the inherent reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks.
Model Architecture
Modality Encoder
The Modality Encoder (ME) is tasked with encoding inputs from diverse modalities IX to obtain corresponding features 𝑭X, formulated as follows:
$$ 𝑭_X=ME_XI_X $$
Various pre-trained encoder options $ME_X$ exist for handling different modalities, where X can be image, video, audio, 3D, or etc. Next, we will offer a concise introduction organized by modality.
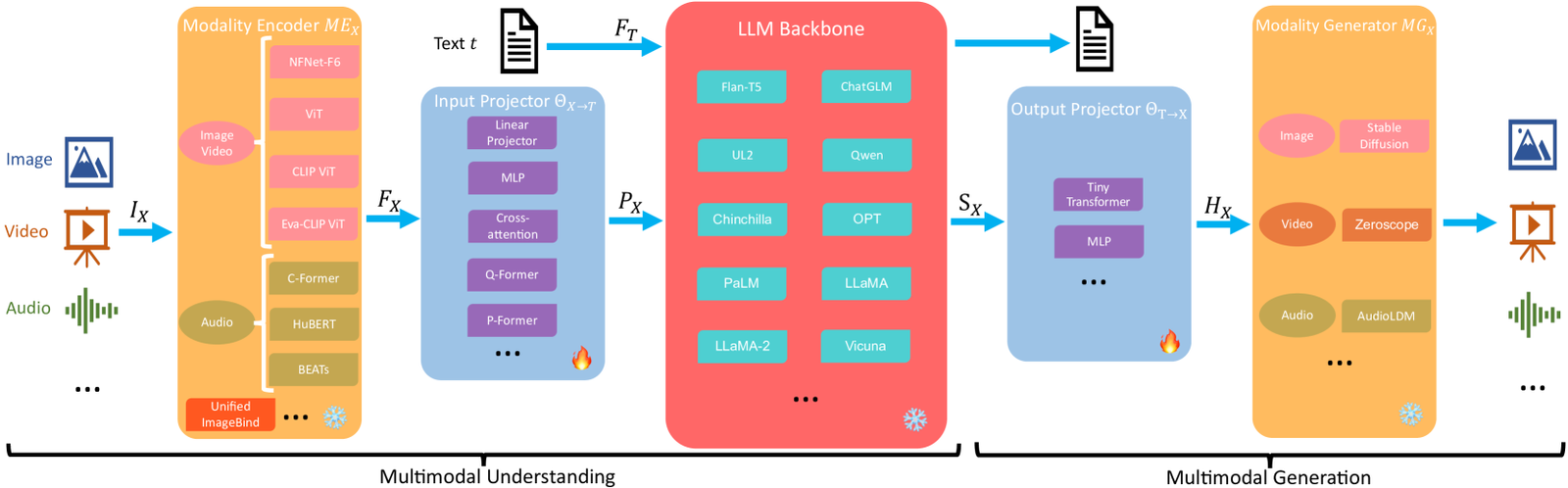
Visual Modality
For images, there are generally four optional encoders: NFNet-F6 Brock et al. (2021), ViT Dosovitskiy et al. (2020), CLIP ViT Radford et al. (2021), and Eva-CLIP ViT Fang et al. (2023). NFNet-F6 is a normalizer-free ResNet He et al. (2016), showcasing an adaptive gradient clipping technique that allows training on extensively augmented datasets while achieving SOTA levels of image recognition.
ViT applies the Transformer Vaswani et al. (2017) to images by first dividing the image into patches. It then undergoes linear projection to flatten the patches, followed by encoding via multiple Transformer blocks.
CLIP ViT builds connections between text and images, comprising a ViT and a text encoder. Utilizing a vast amount of text-image pairs, it optimizes ViT by contrastive learning, treating paired text and images as positive samples and others as negative ones.
Its Eva version stabilizes the training and optimization process of the massive CLIP, offering new directions in expanding and accelerating the expensive training of MM base models. For videos, they can be uniformly sampled to 5 frames, undergoing the same pre-processing as images.
Audio Modality
It is typically encoded by C-Former Chen et al. (2023b), HuBERT Hsu et al. (2021), BEATs Chen et al. (2023f), and Whisper Radford et al. (2023). C-Former employs the CIF alignment mechanism Dong and Xu (2020); Zhang et al. (2022a) for sequence transduction and a Transformer to extract audio features. HuBERT is a self-supervised speech representation learning framework based on BERT Kenton and Toutanova (2019), achieved by the masked prediction of discrete hidden units. BEATs is an iterative audio pre-training framework designed to learn Bidirectional Encoder representations from Audio Transformers.
Training Pipeline
MM-LLMs’ training pipeline can be delineated into two principal stages: MM PT and MM IT.
MM PT
During the PT stage, typically leveraging the X-Text datasets, Input and Output Projectors are trained to achieve alignment among various modalities by optimizing predefined objectives (PEFT is sometimes applied to the LLM Backbone).
MM IT
MM IT is a methodology that entails the fine-tuning of pre-trained MM-LLMs using a set of instruction-formatted datasets Wei et al. (2021). Through this tuning process, MM-LLMs can generalize to unseen tasks by adhering to new instructions, thereby enhancing zero-shot performance. This straightforward yet impactful concept has catalyzed the success of subsequent endeavors in the field of NLP, exemplified by works such as InstructGPT