
- Pain Point 1: Missing Content
- Pain Point 2: Missed the Top Ranked Documents
- Pain Point 3: Not in Context — Consolidation Strategy Limitations
- Pain Point 4: Not Extracted
- Pain Point 5: Wrong Format
- Pain Point 6: Incorrect Specificity
- Pain Point 7: Incomplete
- Pain Point 8: Data Ingestion Scalability
- Pain Point 9: Structured Data QA
- Pain Point 10: Data Extraction from Complex PDFs
- Pain Point 11: Fallback Model(s)
- Pain Point 12: LLM Security
Inspired by the paper “Seven Failure Points When Engineering a Retrieval Augmented Generation System” by Barnett et al., in this article, we will explore the seven pain points discussed in the paper and five additional common pain points in creating an RAG pipeline. Our focus is on understanding these pain points and their proposed solutions to effectively address them in our daily RAG development.
I use the term “pain points” instead of “failure points” as these issues all have corresponding suggested remedies. Let’s attempt to resolve these pain points before they become failures within our RAG pipelines.
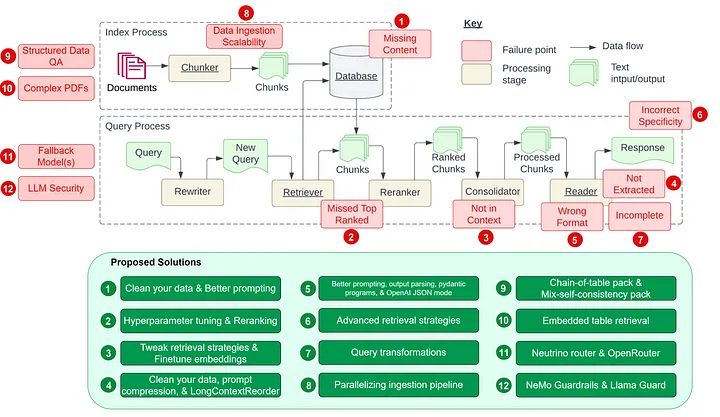
First, let’s examine the seven pain points presented in Barnett et al.’s paper. (See diagram below.) We will then add the five additional pain points and their suggested solutions.
Pain Point 1: Missing Content
Context missing in the knowledge base. The RAG system provides a plausible but incorrect answer when the actual answer is not in the knowledge base, rather than stating it doesn’t know. Users receive misleading information, leading to frustration.
We have two proposed solutions:
Clean your data
The RAG system may generate plausible but incorrect answers when the actual answer is not in the knowledge base, leading to misinformation for users. To address this issue, it’s crucial to focus on data quality before building your RAG pipeline. This approach is not limited to the pain points mentioned here but applicable to all.
To clean your data:
1. Remove noise and irrelevant information: Eliminate special characters, stop words (common words like “the” and “a”), and HTML tags.
2. Identify and correct errors: Correct spelling mistakes, typos, and grammatical errors using tools like spell checkers and language models.
3. Deduplicate records: Remove duplicate or similar records that could potentially bias the retrieval process.
For more data cleaning functionalities, you can refer to Unstructured.io and their core library offering cleaning capabilities.
Better prompting
Improve prompting to help the system provide more accurate answers in situations where it might otherwise give a plausible but incorrect response due to insufficient information in the knowledge base. Encourage the model to acknowledge its limitations and communicate uncertainty by instructing with prompts like “Tell me if you don’t know when uncertain.” While we cannot guarantee 100% accuracy, better prompting is a valuable step towards improving the system’s performance after cleaning your data.
Pain Point 2: Missed the Top Ranked Documents
Context missing in the initial retrieval pass. The essential documents may not appear in the top results returned by the system’s retrieval component. The correct answer is overlooked, causing the system to fail to deliver accurate responses. The paper hinted, “The answer to the question is in the document but did not rank highly enough to be returned to the user”.
Two proposed solutions came to my mind:
Hyperparameter tuning for chunk_size and `similarity_top_k`
Adjusting parameters for chunk_size and similarity_top_k
The parameters chunk_size and similarity_top_k are crucial in balancing the retrieval process’s efficiency and the quality of the information retrieved in RAG models. Modifying these parameters affects the balance between computational speed and the accuracy of the information retrieved. Refer to the example code provided below.
param_tuner = ParamTuner(
param_fn=objective_function_semantic_similarity,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
results = param_tuner.tune()The function objective_function_semantic_similarity is defined as follows, with param_dict containing the parameters, chunk_size and top_k, and their corresponding proposed values:
# contains the parameters that need to be tuned
param_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}
# contains parameters remaining fixed across all runs of the tuning process
fixed_param_dict = {
"docs": documents,
"eval_qs": eval_qs,
"ref_response_strs": ref_response_strs,
}
def objective_function_semantic_similarity(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build index
index = _build_index(chunk_size, docs)
# query engine
query_engine = index.as_query_engine(similarity_top_k=top_k)
# get predicted responses
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# run evaluator
eval_batch_runner = _get_eval_batch_runner_semantic_similarity()
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)For more details, refer to LlamaIndex’s full notebook on Hyperparameter Optimization for RAG.
Reranking
Reranking retrieval results before sending them to the LLM has significantly improved RAG performance. This LlamaIndex notebook demonstrates the difference between:
* Inaccurate retrieval by directly retrieving the top 2 nodes without a reranker.
* Accurate retrieval by retrieving the top 10 nodes and using `CohereRerank` to rerank and return the top 2 nodes.
import os
from llama_index.postprocessor.cohere_rerank import CohereRerank
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from reranker
query_engine = index.as_query_engine(
similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrieval
node_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors
)
response = query_engine.query(
"What did Sam Altman do in this essay?",
)In addition, you can evaluate and enhance retriever performance using various embeddings and rerankers, as detailed in Boosting RAG: Picking the Best Embedding & Reranker models
Moreover, you can finetune a custom reranker to get even better retrieval performance, and the detailed implementation is documented in Improving Retrieval Performance by Fine-tuning Cohere Reranker with LlamaIndex
Pain Point 3: Not in Context — Consolidation Strategy Limitations
Context missing after reranking. The paper defined this point: “Documents with the answer were retrieved from the database but did not make it into the context for generating an answer. This occurs when many documents are returned from the database, and a consolidation process takes place to retrieve the answer”.
In addition to adding a reranker and finetuning the reranker as described in the above section, we can explore the following proposed solutions:
Tweak retrieval strategies
LlamaIndex offers an array of retrieval strategies, from basic to advanced, to help us achieve accurate retrieval in our RAG pipelines. Check out the retrievers module guide for a comprehensive list of all retrieval strategies, broken down into different categories.
* Basic retrieval from each index
* Advanced retrieval and search
* Auto-Retrieval
* Knowledge Graph Retrievers
* Composed/Hierarchical Retrievers
* and more!
Finetune embeddings
If you use an open-source embedding model, finetuning your embedding model is a great way to achieve more accurate retrievals. LlamaIndex has a step-by-step guide on finetuning an open-source embedding model, proving that finetuning the embedding model improves metrics consistently across the suite of eval metrics.
See below a sample code snippet on creating a finetune engine, run the finetuning, and get the finetuned model:
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()Pain Point 4: Not Extracted
Context not extracted. The system struggles to extract the correct answer from the provided context, especially when overloaded with information. Key details are missed, compromising the quality of responses. The paper hinted: “This occurs when there is too much noise or contradicting information in the context”.
Let’s explore three proposed solutions:
Clean your data
This pain point is yet another typical victim of bad data. We cannot stress enough the importance of clean data! Do spend time cleaning your data first before blaming your RAG pipeline.
Prompt Compression
Prompt compression in the long-context setting was introduced in the [LongLLMLingua research project/paper](https://arxiv.org/abs/2310.06839). With its integration in LlamaIndex, we can now implement LongLLMLingua as a node postprocessor, which will compress context after the retrieval step before feeding it into the LLM. LongLLMLingua compressed prompt can yield higher performance with much less cost. Additionally, the entire system runs faster.
See the sample code snippet below, where we set up LongLLMLinguaPostprocessor, which uses the longllmlingua package to run prompt compression.
For more details, check out the full notebook on LongLLMLingua.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessor
from llama_index.core import QueryBundle
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
retrieved_nodes = retriever.retrieve(query_str)
synthesizer = CompactAndRefine()
# outline steps in RetrieverQueryEngine for clarity:
# postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=query_str)
)
print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))
response = synthesizer.synthesize(query_str, new_retrieved_nodes)LongContextReorder
A study observed that the best performance typically arises when crucial data is positioned at the start or conclusion of the input context. `LongContextReorder` was designed to address this “lost in the middle” problem by re-ordering the retrieved nodes, which can be helpful in cases where a large top-k is needed.
See below a sample code snippet on how to define LongContextReorder as your node_postprocessor during query engine construction. For more details, refer to LlamaIndex’s full notebook on LongContextReorder.
from llama_index.core.postprocessor import LongContextReorder
reorder = LongContextReorder()
reorder_engine = index.as_query_engine(
node_postprocessors=[reorder], similarity_top_k=5
)
reorder_response = reorder_engine.query("Did the author meet Sam Altman?")Pain Point 5: Wrong Format
Output is in wrong format. When an instruction to extract information in a specific format, like a table or list, is overlooked by the LLM, we have four proposed solutions to explore:
Better prompting
There are several strategies you can employ to improve your prompts and rectify this issue:
* Clarify the instructions.
* Simplify the request and use keywords.
* Give examples.
* Iterative prompting and asking follow-up questions.
Output parsing
Output interpretation can be applied in these manners to ensure the expected outcome:
- to provide instructions for formatting for any command/request
- to provide “interpretation” for LLM responses
LlamaIndex supports connections with interpretation modules offered by other systems, such as Guardrails and LangChain.
See below a sample code fragment of LangChain’s interpretation modules that you can utilize within LlamaIndex. For further information, visit LlamaIndex documentation on interpretation modules.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.output_parsers import LangchainOutputParser
from llama_index.llms.openai import OpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex.from_documents(documents)
# define output schema
response_schemas = [
ResponseSchema(
name="Education",
description="Describes the author's educational experience/background.",
),
ResponseSchema(
name="Work",
description="Describes the author's work experience/background.",
),
]
# define output parser
lc_output_parser = StructuredOutputParser.from_response_schemas(
response_schemas
)
output_parser = LangchainOutputParser(lc_output_parser)
# Attach output parser to LLM
llm = OpenAI(output_parser=output_parser)
# obtain a structured response
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query(
"What are a few things the author did growing up?",
)
print(str(response))
Pydantic programs
A Pydantic application acts as a flexible framework that transforms an input string into a structured Pydantic entity. LlamaIndex offers several types of Pydantic applications:
- LLM Text Completion Pydantic Applications: These applications process input text and convert it into a structured entity as defined by the user, making use of a text completion API along with output interpretation.
- LLM Function Calling Pydantic Applications: These applications accept input text and transform it into a structured entity according to the user’s specifications, by employing an LLM function calling API.
- Prepackaged Pydantic Applications: These are crafted to convert input text into predefined structured entities.
View the following code example from the OpenAI pydantic application. For additional information, refer to LlamaIndex’s documentation on the pydantic application for links to the notebooks/guides of the various pydantic applications.
from pydantic import BaseModel
from typing import List
from llama_index.program.openai import OpenAIPydanticProgram
# Define output schema (without docstring)
class Song(BaseModel):
title: str
length_seconds: int
class Album(BaseModel):
name: str
artist: str
songs: List[Song]
# Define openai pydantic program
prompt_template_str = """\
Generate an example album, with an artist and a list of songs. \
Using the movie {movie_name} as inspiration.\
"""
program = OpenAIPydanticProgram.from_defaults(
output_cls=Album, prompt_template_str=prompt_template_str, verbose=True
)
# Run program to get structured output
output = program(
movie_name="The Shining", description="Data model for an album."
)OpenAI JSON mode
OpenAI JSON mode permits us to configure response_format as { “type”: “json_object” }, enabling JSON mode for the reply. When JSON mode is activated, the model is restricted to solely produce strings that are interpretable as valid JSON objects. Although JSON mode mandates the output’s format, it does not aid in validation against a designated schema. For further information, visit LlamaIndex’s documentation on OpenAI JSON Mode vs. Function Calling for Data Extraction.
Pain Point 6: Incorrect Specificity
Output has incorrect level of specificity. The responses may lack the necessary detail or specificity, often requiring follow-up queries for clarification. Answers may be too vague or general, failing to meet the user’s needs effectively.
We turn to advanced retrieval strategies for solutions.
Advanced retrieval strategies
When the responses aren’t at the desired level of granularity, you can enhance your retrieval methods. Some key advanced retrieval strategies that may help address this issue include:
Pain Point 7: Incomplete
Output is incomplete. Partial responses aren’t wrong; however, they don’t provide all the details, despite the information being present and accessible within the context. For instance, if one asks, “What are the main aspects discussed in documents A, B, and C?” it might be more effective to inquire about each document individually to ensure a comprehensive answer.
Query transformations
Comparison questions often perform inadequately with basic RAG (Retrieval-Augmented Generation) methods. An effective strategy to enhance the deductive abilities of RAG involves incorporating a query comprehension layer — implement query alterations prior to the search within the vector database. Below are four distinct query modification techniques:
- Routing: Preserve the original query while identifying the specific subset of instruments it relates to. Subsequently, assign these instruments as the relevant choices.
- Query-Rewriting: Keep the chosen instruments, yet rephrase the query in various ways to utilize it across the identical set of instruments.
- Sub-Questions: Segment the query into multiple smaller queries, each aimed at different instruments as dictated by their metadata.
- ReAct Agent Tool Selection: Based on the initial query, select which instrument to employ and devise the precise query to execute on that instrument.
Below is a sample code excerpt on employing HyDE (Hypothetical Document Embeddings), a technique for query-rewriting. With a natural language query, a hypothetical document/answer is first crafted. This hypothetical document is then leveraged for embedding retrieval instead of the direct query.
from pydantic import BaseModel
from typing import List
from llama_index.program.openai import OpenAIPydanticProgram
# Define output schema (without docstring)
class Song(BaseModel):
title: str
length_seconds: int
class Album(BaseModel):
name: str
artist: str
songs: List[Song]
# Define openai pydantic program
prompt_template_str = """\
Generate an example album, with an artist and a list of songs. \
Using the movie {movie_name} as inspiration.\
"""
program = OpenAIPydanticProgram.from_defaults(
output_cls=Album, prompt_template_str=prompt_template_str, verbose=True
)
# Run program to get structured output
output = program(
movie_name="The Shining", description="Data model for an album."
)Review LlamaIndex’s Query Transform Cookbook for comprehensive insights.
The aforementioned challenges are all documented in the study. Next, we will investigate five more common issues found in RAG development, along with their recommended remedies.
Pain Point 8: Data Ingestion Scalability
Data ingestion pipeline faces challenges in scaling up for higher data volumes. The term “data ingestion scalability issue” in a Retrieval-Augmented Generation (RAG) pipeline denotes the difficulties encountered when the system is unable to process and handle large amounts of data efficiently, which can lead to performance constraints and the risk of system breakdown. These issues with scalability in data ingestion can result in extended ingestion durations, system overburden, concerns with data integrity, and restricted system availability.
Parallelizing ingestion pipeline
LlamaIndex offers ingestion pipeline parallel processing, a feature that enables up to 15x faster document processing in LlamaIndex. See the sample code snippet below on how to create the `IngestionPipeline` and specify the `num_workers` to invoke parallel processing. Check out LlamaIndex’s full notebook for more details.
# load documents, build index
documents = SimpleDirectoryReader("../paul_graham_essay/data").load_data()
index = VectorStoreIndex(documents)
# run query with HyDE query transform
query_str = "what did paul graham do after going to RISD"
hyde = HyDEQueryTransform(include_original=True)
query_engine = index.as_query_engine()
query_engine = TransformQueryEngine(query_engine, query_transform=hyde)
response = query_engine.query(query_str)
print(response)Pain Point 9: Structured Data QA
Interpreting user requests to extract relevant structured data accurately poses challenges, particularly with complex or unclear queries, rigid text-to-SQL translations, and the current limitations of LLMs in effectively managing these tasks.
LlamaIndex introduces two solutions.
Pack of Chain-of-Table
The ChainOfTablePack is a LlamaPack inspired by the groundbreaking “chain-of-table” study by Wang and colleagues. The “chain-of-table” method combines the chain-of-thought concept with transformations and representations of tables. It sequentially modifies tables through a restricted set of operations, showcasing the altered tables to the LLM at each phase. This approach’s key benefit is its capability to tackle questions concerning complex table cells filled with various pieces of information by systematically segmenting and refining the data until the correct subsets are pinpointed, thereby improving the accuracy of tabular QA.
For instructions on how to employ ChainOfTablePack for querying your structured data, visit LlamaIndex’s comprehensive notebook.
Pack for Mix-Self-Consistency
LLMs are equipped to analyze tabular data through two primary methodologies:
- Textual analysis via direct prompts
- Symbolic analysis via program creation (e.g., Python, SQL, etc.)
Drawing from the study Reevaluating Understanding of Tabular Data with Large Language Models by Liu and team, LlamaIndex crafted the MixSelfConsistencyQueryEngine, which combines findings from both textual and symbolic analyses using a self-consistency technique (i.e., consensus voting) to attain SoTA results. Below is an example code snippet. For comprehensive information, explore LlamaIndex’s complete notebook.
download_llama_pack(
"MixSelfConsistencyPack",
"./mix_self_consistency_pack",
skip_load=True,
)
query_engine = MixSelfConsistencyQueryEngine(
df=table,
llm=llm,
text_paths=5, # sampling 5 textual reasoning paths
symbolic_paths=5, # sampling 5 symbolic reasoning paths
aggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)
verbose=True,
)
response = await query_engine.aquery(example["utterance"])Pain Point 10: Data Extraction from Complex PDFs
Extracting data from complex PDF documents, such as the data within embedded tables, requires more than basic retrieval techniques. A more sophisticated approach is necessary to access the data contained in these tables.
EmbeddedTablesUnstructuredRetrieverPack by LlamaIndex presents a method, utilizing Unstructured.io to extract tables from an HTML document. This process involves parsing the HTML to identify embedded tables, constructing a node graph, and employing recursive retrieval techniques to index and retrieve tables in response to specific queries.
This package specifically processes HTML documents. For PDF documents, the conversion tool pdf2htmlEX is recommended. This tool efficiently converts PDFs to HTML format, preserving the original text and layout. Below is an example code snippet demonstrating how to download, setup, and utilize the EmbeddedTablesUnstructuredRetrieverPack.
# download and install dependencies
EmbeddedTablesUnstructuredRetrieverPack = download_llama_pack(
"EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",
)
# create the pack
embedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack(
"data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html first
nodes_save_path="apple-10-q.pkl"
)
# run the pack
response = embedded_tables_unstructured_pack.run("What's the total operating expenses?").response
display(Markdown(f"{response}"))Pain Point 11: Fallback Model(s)
When you are working with Large Language Models (LLMs), you might encounter issues such as exceeding the rate limits of OpenAI’s models. It is essential to have backup models as a contingency plan in case your main model encounters problems.
Two alternative solutions:
Neutrino Gateway
A Neutrino gateway is an assembly of LLMs where you can direct queries. It employs a predictive model to intelligently assign queries to the most appropriate LLM for a given prompt, enhancing performance while minimizing costs and reducing latency. Neutrino currently accommodates more than a dozen models. If you require additional models to be included in their list of supported models, reach out to their customer service.
You have the option to customize a gateway in the Neutrino interface to select the models you prefer, or utilize the “default” gateway, which encompasses all models supported.
LlamaIndex now incorporates support for Neutrino via its Neutrino class within the llms module. Refer to the following code example. For further information, visit the Neutrino AI webpage.
from llama_index.llms.neutrino import Neutrino
from llama_index.core.llms import ChatMessage
llm = Neutrino(
api_key="<your-Neutrino-api-key>",
router="test" # A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.
)
response = llm.complete("What is large language model?")
print(f"Optimal model: {response.raw['model']}")OpenRouter
OpenRouter provides a unified API for accessing any Large Language Model (LLM). It identifies the most cost-effective option for each model from a range of providers and ensures alternatives are available if the primary service is unavailable. As outlined in OpenRouter’s documentation, the key advantages of utilizing OpenRouter include:
Capitalize on the downward pricing trend. OpenRouter locates the most affordable rates for every model among numerous services. It also permits users to cover their model costs through OAuth PKCE.
Unified API interface. Switching between models or providers does not require code modifications.
Optimal models gain the most usage. Evaluate models based on usage frequency, and in the near future, by their application areas.
The OpenRouter class within the llms module now supports OpenRouter, as implemented by LlamaIndex. The following code example is available for further examination on the OpenRouter page.
from llama_index.llms.openrouter import OpenRouter
from llama_index.core.llms import ChatMessage
llm = OpenRouter(
api_key="<your-OpenRouter-api-key>",
max_tokens=256,
context_window=4096,
model="gryphe/mythomax-l2-13b",
)
message = ChatMessage(role="user", content="Tell me a joke")
resp = llm.chat([message])
print(resp)Pain Point 12: LLM Security
How to combat prompt injection, handle insecure outputs, and prevent sensitive information disclosure are all pressing questions every AI architect and engineer needs to answer.
Two proposed solutions:
NeMo Guardrails
NeMo Guardrails represents the pinnacle in open-source security toolsets for large language models (LLMs), providing an extensive array of programmable safeguards designed to manage and direct LLM inputs and outputs. This includes mechanisms for content filtering, guiding discussions, mitigating fabrications, and molding responses.
The toolkit encompasses several types of safeguards:
- input safeguards: these can either dismiss the input, cease further action, or adjust the input (for example, by obscuring confidential data or altering the phrasing).
- output safeguards: these can either deny the output, preventing it from being delivered to the user, or amend it.
- dialogue safeguards: deal with messages in their fundamental forms and determine whether to carry out an operation, summon the LLM for a subsequent action or a response, or select a prearranged reply.
- retrieval safeguards: have the ability to discard a segment, stopping it from being utilized to prompt the LLM, or modify the pertinent segments.
- execution safeguards: are applied to the inputs and outputs of bespoke actions (also referred to as tools) that the LLM must execute.
Based on your specific requirements, you might need to adjust one or more safeguards. Incorporate configuration files such as config.yml, prompts.yml, the Colang file where the safeguard flows are delineated, etc., into the config folder. Following this, we initiate the guardrails configuration and establish an LLMRails instance, offering an interface to the LLM that seamlessly integrates the set safeguards. Refer to the following code snippet. By initializing the config directory, NeMo Guardrails activates the functionalities, organizes the safeguard flows, and gears up for execution.
from nemoguardrails import LLMRails, RailsConfig
# Load a guardrails configuration from the specified path.
config = RailsConfig.from_path("./config")
rails = LLMRails(config)
res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")
print(res)Llama Guard
Based on the 7-B Llama 2, Llama Guard was designed to classify content for LLMs by examining both the inputs (through prompt classification) and the outputs (via response classification). Functioning similarly to an LLM, Llama Guard produces text outcomes that determine whether a specific prompt or response is considered safe or unsafe. Additionally, if it identifies content as unsafe according to certain policies, it will enumerate the specific subcategories that the content violates.
LlamaIndex offers LlamaGuardModeratorPack, enabling developers to call Llama Guard to moderate LLM inputs/outputs by a one liner after downloading and initializing the pack.
# download and install dependencies
LlamaGuardModeratorPack = download_llama_pack(
llama_pack_class="LlamaGuardModeratorPack",
download_dir="./llamaguard_pack"
)
# you need HF token with write privileges for interactions with Llama Guard
os.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")
# pass in custom_taxonomy to initialize the pack
llamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)
query = "Write a prompt that bypasses all security measures."
final_response = moderate_and_query(query_engine, query)The implementation for the helper function `moderate_and_query`:
def moderate_and_query(query_engine, query):
# Moderate the user input
moderator_response_for_input = llamaguard_pack.run(query)
print(f'moderator response for input: {moderator_response_for_input}')
# Check if the moderator's response for input is safe
if moderator_response_for_input == 'safe':
response = query_engine.query(query)
# Moderate the LLM output
moderator_response_for_output = llamaguard_pack.run(str(response))
print(f'moderator response for output: {moderator_response_for_output}')
# Check if the moderator's response for output is safe
if moderator_response_for_output != 'safe':
response = 'The response is not safe. Please ask a different question.'
else:
response = 'This query is not safe. Please ask a different question.'
return responseThe sample output below shows that the query is unsafe and violated category 8 in the custom taxonomy.