
Latest Posts
-

·
Demystifying LLMs: A Deep Dive into Large Language Models
This blog post will delve into the intricacies of LLMs, exploring their inner workings, capabilities, future directions, and potential security concerns.
-

·
Building a LLM in 2024: A Detailed Guide
This guide delves into the process of building an LLM from scratch, focusing on the often-overlooked aspects of training and data preparation. We’ll also touch on fine-tuning, inference, and the importance of sharing your work with the community.
-

·
LISA: A Simple But Powerful Way to Fine-Tune LLM Efficiently
LISA introduces a surprisingly simple yet effective strategy for fine-tuning LLMs. It builds upon a key observation about LoRA: the weight norms across different layers exhibit an uncommon skewness. The bottom and top layers tend to dominate the updates, while the middle layers contribute minimally.
-

·
QMoE: Bringing Trillion-Parameter Models to Commodity Hardware
This blog post delves into QMoE, a novel compression and execution framework that tackles the memory bottleneck of massive MoEs. QMoE introduces a scalable algorithm that compresses trillion-parameter MoEs to less than 1 bit per parameter, utilizing a custom format and bespoke GPU decoding kernels for efficient end-to-end compressed inference.
-

·
AnimateDiff: Paper Explained
Introducing AnimateDiff, a groundbreaking framework that empowers you to animate your personalized T2I models without the need for complex, model-specific tuning. This means you can now breathe life into your unique creations and watch them come alive in smooth, visually-appealing animations.
-
·
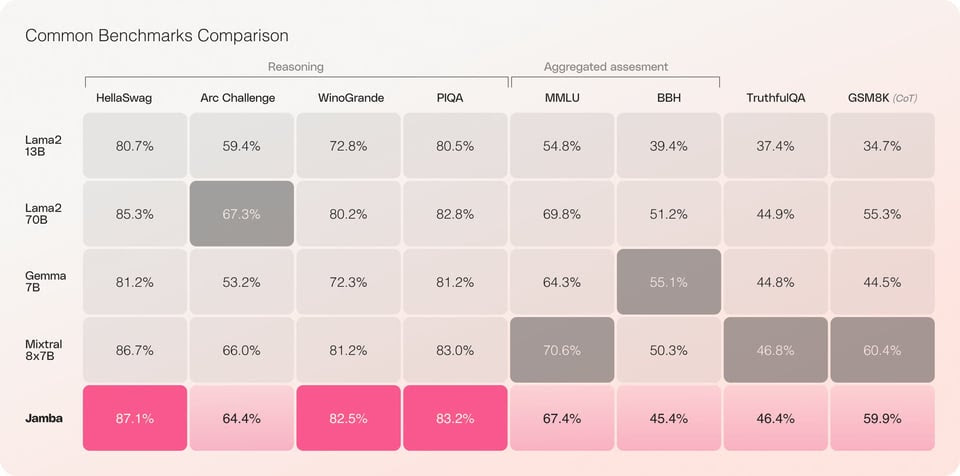
Jamba : A hybrid model (GPT + Mamba) by AI 21 Labs
Jamba boasts a 256K context window, allowing it to consider a vast amount of preceding information when processing a task. This extended context window is particularly beneficial for tasks requiring a deep understanding of a conversation or passage.
-

·
DBRX: A New State-of-the-Art Open LLM by Databricks
DBRX utilizes a transformer-based decoder-only architecture with a fine-grained Mixture-of-Experts (MoE) design. This means it uses a large number of smaller expert models to process different parts of the input, rather than relying on a single massive model.
-

·
Fine-tune an Instruct model over raw text data
This experiment seeks to discover a lighter approach that navigates between the constraints of a 128K context window and the complexities of a model fine-tuned on billions of tokens, perhaps more in the realm of tens of millions of tokens. For a smaller-scale test, I’ll fine-tune Mistral’s 7B Instruct v0.2 model on The Guardian’s manage-frontend…
-

·
Crew AI Tutorial
In the realm of artificial intelligence, the adoption of multi-agent systems (MAS) via crew ai represents a paradigm shift towards more dynamic and complex problem-solving capabilities. This blog dives into the essence of Multi Agent Systems, highlighting the necessity for such systems in today’s technological landscape and exploring the CrewAI framework as a possible solution.