
Latest Posts
-
![Last week in AI [#1]](https://originshq.com/wp-content/uploads/2024/02/Gemini-Generated-Image-1140x1140.jpeg)
·
Last week in AI [#1]
Here are the latest updates : Open Source AI Cookbook: The AI community received a treasure trove of resources with the launch of the Open Source AI Cookbook. This collection of notebooks, powered by open-source tools, is designed to empower AI builders with practical, hands-on experience. Dive into the repository and start exploring! Read more.…
-

·
Utilizing LangChain ReAct Agents for Resolving Complex Queries in RAG Frameworks
Effective for processing intricate inquiries within internal documents stepwise using ReAct and Open AI Tools agents. Purpose The fundamental RAG chat interfaces I’ve developed before utilizing key LangChain elements like vectorstore, retrievers, etc., have proven effective. Based on the internal data supplied, they manage simple inquiries such as “What is the parental leave policy in…
-

·
Pioneering Advanced RAG: Paving the Way for AI’s Next Era
Mastering Sophisticated RAG: The Key to Unlocking Next-Generation AI Applications Introduction Retrieval-Augmented Generation (RAG) marks a groundbreaking leap in generative AI technology, merging effective data search with the capabilities of expansive language models. At its heart, RAG utilizes vector-based search to sift through relevant and pre-existing data, merging this information with the user’s request, and…
-

·
Cut RAG costs by 80 percent
Accelerating Inference With Prompt Compression The inference process is one of the things that greatly increases the money and time costs of using large language models. This problem augments considerably for longer inputs. Below, you can see the relationship between model performance and inference time. High-speed models, which produce more tokens each second, generally achieve…
-

·
RAG with Rank Fusion
Having been immersed in the exploration of search technologies for nearly ten years, I can assert with confidence that nothing has matched the transformative impact of the recent emergence of Retrieval Augmented Generation (RAG). This framework is revolutionizing the domain of search and information retrieval through the application of vector search alongside generative AI, delivering…
-

·
A Guide on 12 Tuning Strategies for Production RAG Systems
This article covers the following “hyperparameters” sorted by their relevant stage. In the ingestion stage of a RAG pipeline, you can achieve performance improvements by: And in the inferencing stage (retrieval and generation), you can tune: Note that this article covers text-use cases of RAG. For multimodal RAG applications, different considerations may apply. Ingestion Stage…
-
·
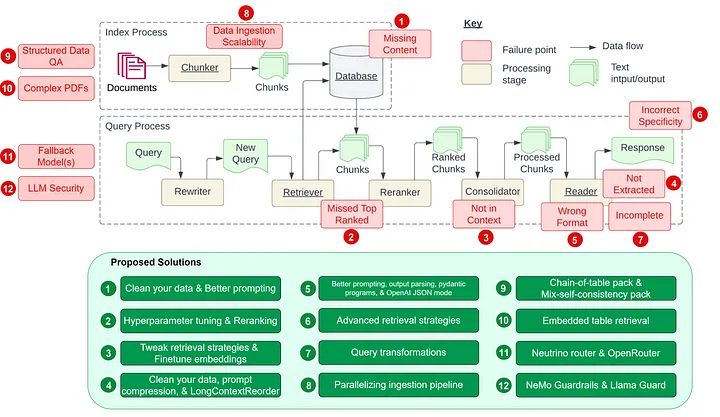
12 RAG Pain Points and Solutions
Inspired by the paper “Seven Failure Points When Engineering a Retrieval Augmented Generation System” by Barnett et al., in this article, we will explore the seven pain points discussed in the paper and five additional common pain points in creating an RAG pipeline. Our focus is on understanding these pain points and their proposed solutions…
-

·
How do you incorporate domain knowledge and prior information into YOLO models?
Now that we’ve discussed different ways to incorporate domain knowledge and prior information into YOLO (You Only Look Once) models, let’s delve deeper into these techniques with some code snippets and practical examples. 1. Data Augmentation Data augmentation is a powerful technique to enrich the training dataset without collecting new data. It involves artificially creating…
-

·
How to Efficiently Tune Large Language Models with Early-Exiting
In the rapidly evolving world of deep learning, the efficiency of model training and inference has become as crucial as model accuracy itself. Large Language Models (LLMs) like GPT and BERT have pushed the boundaries of what’s possible in natural language processing, but their immense size and complexity present a significant challenge. The computational cost…