
In the evolving field of natural language processing, the efficiency and effectiveness of large language models (LLMs) are paramount. Among various model compression techniques, such as distillation, tensor decomposition, pruning, and quantization, we focus on an innovative approach called SliceGPT. This method demonstrates the capability to compress large models using a single GPU in just a few hours, while maintaining competitive performance on generation and downstream tasks, even without the need for further retraining (RFT).
Understanding Pruning in Language Models
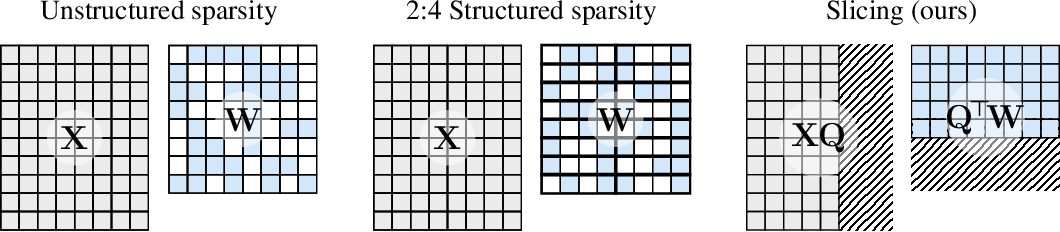
Pruning is a technique that enhances computational efficiency by setting certain elements of a model’s weight matrices to zero. Optionally, it can also involve updating surrounding elements to compensate for this change. The outcome is a sparse pattern within the matrices, allowing the model to skip some floating-point operations during the forward pass of the neural network. The extent of computational gain achieved depends on the level of sparsity and the sparsity pattern, with more structured sparsity yielding greater benefits.
The SliceGPT Approach
SliceGPT differs from traditional pruning methods by “slicing off” entire rows or columns of the weight matrices. Before this slicing, a crucial transformation is applied to the network, ensuring minimal impact on the model’s predictive capabilities.
Computational Invariance in Transformer Networks
SliceGPT leverages a computational invariance inherent in the transformer architecture. It involves applying an orthogonal transformation ( Q ) to the output of one component, counterbalanced in the subsequent component. This method proves beneficial, especially with the RMSNorm operation between blocks, which remains unaffected by these transformations.
Layernorm Transformers Can Be Converted To Rmsnorm
To utilize this computational invariance, LayerNorm-connected networks are first converted to RMSNorm. This is achieved by absorbing the linear blocks of LayerNorm into adjacent blocks, thus making the network compatible with the SliceGPT method.
A Transformation Per Block
Upon converting every LayerNorm in the transformer to RMSNorm, we can then apply a distinct orthogonal matrix ( Q ) at each block. This approach emerged from observing misaligned signals across different network blocks, necessitating a unique transformation at each stage.
Slicing: The Core of SliceGPT
The principle of SliceGPT is akin to that of Principal Component Analysis (PCA), where the aim is to derive a lower-dimensional representation ( Z ) of a data matrix ( X ), along with an approximate reconstruction of ( X ). Similarly, SliceGPT strategically removes parts of the network while ensuring the integrity and efficiency of the model.