
The ever-growing demand for online shopping underscores the need for a more immersive shopping experience, allowing shoppers to virtually ‘try’ any product from any category (clothes, shoes, furniture, decoration, etc.) within their personal environments. The concept of a Virtual Try-All (Vit-All) model hinges on its functionality as an advanced semantic image composition tool. In practice, this involves taking an image from a user, selecting a region within that image, and using a reference product image from an online catalog to semantically insert the product into the selected area while preserving its details.
What is Difuse to Choose
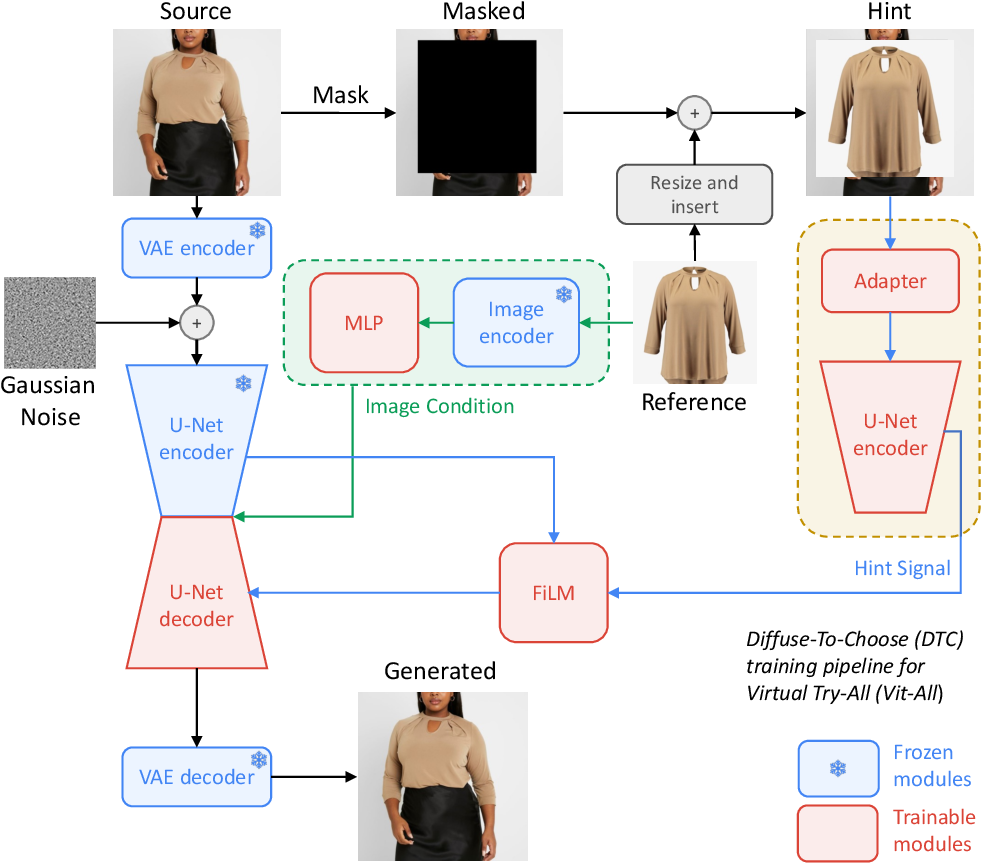
In this work, we introduce “Diffuse to Choose” (DTC), a novel diffusion in-painting approach designed for the Vit-All application. DTC, a latent diffusion model, effectively incorporates fine-grained cues from the reference image into the main U-Net decoder using a secondary U-Net encoder. Inspired by ControlNet [42] , we integrate a pixel-level “hint” into the masked region of an empty image, which is then processed through a shallow convolutional network, ensuring dimensional alignment with the masked image processed by the Variational Auto-encoder (VAE). DTC harmoniously blends the source and reference images, maintaining the integrity and details of the reference image. To further enhance alignment of basic features such as color, we employ perceptual loss using a pre-trained VGG model.
The process initiates with masking the source image, followed by inserting the reference image within the masked area. This pixel-level ‘hint’ is then adapted by a shallow CNN to align with the VAE output dimensions of the source image. Subsequently, a U-Net Encoder processes the adapted hint. Then, at each U-Net scale, a FiLM module affinely aligns the skipconnected features from the main U-Net Encoder and pixel-level features from the hint U-Net Encoder. Finally, these aligned feature maps, in conjunction with the main image conditioning, facilitate the inpainting of the masked region. Red indicates trainable modules and blue indicates frozen modules.