

Fine-tune a modern chatbot with minimal conversational data for under $10
Purpose
Getting a modern chatbot to uphold it’s capabilities on your own data remains a complex task. Context window sizes are increasing rapidly with leading products like Gemini 1.5 Pro’s and Claude 3’s big leap to a 1 million token capacity. However, a company like The Guardian, where We currently work, has countless code repositories containing hundreds of millions of tokens worth of data.
The recently announced Devin by Cognition Labs likely uses clever RAG techniques to complete it’s tasks, but relying on injecting all information into the context window can be problematic. The consensus in the community seems to be that GPT-4 128k can retain great performance for up to around 60K tokens, which isn’t a lot. Even then, retaining the great performance requires better and trickier prompting as the amount of tokens grow. Because of these limitations, it seems likely that the most capable models in the near future will use a combination of good prompting, RAG and fine-tuning. For example, for a code assistant tool, the most recent code could be retrieved through a RAG pipeline. A fine-tuned model could then analyse and reason about this code more effectively than a non fine-tuned model, pointing out any edge cases and risks it may have learned from elsewhere. Additionally, the fine-tuned model would adopt the organisation’s coding conventions and best practices, allowing it to provide more insightful guidance to employees.
We found limited resources online about high-performing chatbots fine-tuned on smaller datasets. Instead, most research introduces models like BioMistral, which achieve success using large 3 billion token datasets, requiring significant budget and expertise.
This experiment seeks to discover a lighter approach that navigates between the constraints of a 128K context window and the complexities of a model fine-tuned on billions of tokens, perhaps more in the realm of tens of millions of tokens. For a smaller-scale test, I’ll fine-tune Mistral’s 7B Instruct v0.2 model on The Guardian’s manage-frontend repository (the dataset being 1.6 million tokens).
The goal of this article was to create a reproducible set of instructions for cost-effective model fine-tuning using easily accessible hardware. Emphasis was placed on ease of use, minimizing trial and error, and maximizing the use of raw text data over labeled conversational data. Hopefully any software developer, with zero experience in deep learning engineering, can pick up the notebook and train their own model with ease.
I’ll outline the data used, highlight the best hyperparameters and their results, then conclude with a technical explanation for their effectiveness.
Training
A100 40GB
We used a Nvidia A100 40GB from Colab for all training except for one run where We used an H100 80GB.
Unsloth
We used the Unsloth library for faster and more memory efficient training. This blog post gives a good summary on how the Unsloth library works under the hood and shows benchmarks for training speed increases and memory saving.
Differences in training approach to start of the art fine-tuned models
Modern examples of fine-tuning to teach a model new domain-specific knowledge include BioMistral and xFinance. xFinance continues the pre-training of the Llama 7B base model, i.e.: the non-instruct version. It uses LoRA. The model is first trained on over 216,626 documents, totalling 236 million tokens. It is then further fine-tuned on 25,000 samples of finance-based conversational data. Similar to standard chatbot training, this approach begins with training on raw text data, lacking instruction tokens or structured conversational elements, and then transitions to training over exclusively conversational data. BioMistral takes a similar approach, though interestingly it starts fine-tuning off the Mistral 7B Instruct v0.2 model.
My approach combines both the raw dataset and the annotated dataset in the same training run as this approach produced the best results. Only one training run is done.
TRL’s SFTtrainer
We used the [SFTtrainer](https://huggingface.co/docs/trl/en/sft_trainer) from the [trl](https://huggingface.co/docs/trl/en/index) library. We saw it was used in this Unsloth demo notebook with good results. This is a wrapper over the default HuggingFace trainer. We couldn’t find much documentation on how the SFTtrainer extends it, and the code suggests minimal changes. It appears to prepare the dataset for self-supervised training by setting target labels identical to input_ids (see these lines of code). It sets the target labels to be the same as the input_ids. Here’s an example of a notebook doing the same thing with the default HuggingFace trainer. This just boils down to next token prediction using the default trainer provided by HuggingFace, nothing fancy. The only difference in training between the “raw text data” and conversational data are the addition of the special instruction tokens “[INST]” and “[/INST]” that Mistral Instruct has been trained to recognise. Refer to the cell outputs in the notebook to see what the dataset looks like.
Creating the raw dataset
My raw dataset consists of the repo’s wiki, a snapshot of the main branch from December, and the last 100 pull requests including comments and code changes. We chunked it so each sample was max 8192 tokens.
Scraping the wiki
We just copied and pasted each page into a text file for this
Scraping the codebase
We wrote a Python script that ran locally and wrote all files to a text file in the following format:
- File: productSwitchTypes.ts
Content:
export type ProductSwitchType =
| 'to-recurring-contribution'
| 'recurring-contribution-to-supporter-plus';
export interface PreviewResponse {
amountPayableToday: number;
supporterPlusPurchaseAmount: number;
contributionRefundAmount: number;
nextPaymentDate: string;
checkChargeAmountBeforeUpdate: boolean;
}
- File: productTypes.ts
Content:
...
...
...Scraping PR data
The corresponding cell in the Colab notebook will produce an output like so for this PR:
PR #2989: Create devcontainer.json
URL: https://github.com/octocat/Hello-World/pull/2989
Description: None
Created at: 2024-02-26T11:39:03Z
Merged at: None
File: .devcontainer/devcontainer.json, Status: added
Changes: @@ -0,0 +1,5 @@
+{
+ "image": "mcr.microsoft.com/devcontainers/universal:2",
+ "features": {
+ }
+}Generating conversational data
Despite the title of this article, We did use a bit of labeled conversational data, but it is synthetically and easily generated. This doesn’t match the quality of carefully curated datasets, but synthetic data is becoming common (I read somewhere it amounted for around 50% of the datasets on HuggingFace). While it won’t lead to amazing chatbot performance, the intuition is it may help mitigate any catastrophic forgetting and performance dips, and it’s also an easy way of augmenting our dataset. We used 3 methods of generating the synthetic data:
- For each Wiki page, We used the GPT-4 Turbo API to generate a few QA samples based on the provided text. This resulted in roughly 300 QA pairs.
- For each Wiki page, We created a specific instruction or question. For instance, on the ‘Fastly & Caching’ page, the instruction might be ‘Walk me through how Fastly is used in
manage-frontend.’ The response is then simply the contents of that Wiki page. - Similar to the previous step, for each file in the codebase, We created a question for it. E.g.: “What does the
package.jsonfile look like in themanage-frontendrepo?” We then prefix each code file with the date of the codebase snapshot used for training, i.e.: “As of December 2023, thepackage.jsonfile looks like so: ”
The QA data was exported to a JSONL file, the following format is recommended as many tokenizers have a function called [apply_chat_template](https://colab.research.google.com/drive/11X5ptOe3zbFE2s1AeHu-gynwAbkE-7Zn#scrollTo=jSpOjMopIRWk) which takes in the list inside the messages property in each line. Here is an example format below:
{"messages":[{"role":"user","content":"What is the capital of France?"},{"role":"assistant","content":"The capital of France is Paris."}]}
{"messages":[{"role":"user","content":"What is the capital of England?"},{"role":"assistant","content":"The capital of England is London."}]}I’m using 10% of this conversational data for the validation dataset.
Training the model
Hyperparameter sweeps
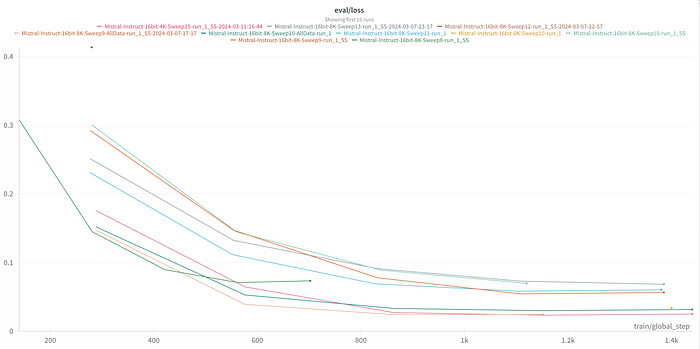
We used a manual search. My intuition was that the LoRA rank, batch size and learning rate would affect model performance the most. We therefore started with a wide range of these hyperparameters and then iteratively narrowed down the search space based on the performance of the initial sweeps. A learning rate of 2e-5 appeared optimal, which seems to be standard for fine-tuning Mistral. BioMistral continued fine-tuning the instruct model v0.2 with 0 warm up, a cosine scheduler and a learning rate of 2e-5. As We upped the rank and lowered the batch size the eval loss improved. However, it’s important to note that just lowering eval batch size can naturally improve validation loss due to less samples being validated at once, so it’s always good to check your model manually after it’s done training!
The sweeps in the image below all use a rank of either 512 or 768, with varying alphas; either 1x, 1.5x or 2x the rank. The batch sizes are either 1, 2 or 4. You can see the final hyperparameters We used in here.
Once We found the optimal hyperparameters, We re-ran the training to include all data to make the most of the little data We had, as is common practice. These runs are noted by the All-Data tag on the end of the sweep name.
Each sweep took under 3 hours, only a few pounds in Colab. All sweeps probably cost me somewhere between £40 and £50.
Note: We accidentally included our Q&A validation data in our raw text data (I forgot We copied and pasted it into one of our text files 🙃). However, re-running a couple sweeps without this confirmed that the selected hyperparameters remain robust and the validation loss was not much higher, with the optimal run having about a 0.12 eval loss. This is still very low, and indicates almost perfect performance, which is not the case. Therefore the eval strategy needs a bit of investigation and bettering.
Expectations
My expectations of this experiment were low. With limited online resources on projects of a similar scale and setup, We assumed there were obvious technical reasons for this. My assumption was a lot of catastrophic forgetting, random hallucinations, and a significant drop in performance, though We thought maybe it could answer a simple question like “What tech stack does manage-frontend use?”.
Results
This notebook includes a Gradio app for experimenting with your chatbot.
The results were better than expected:
The following response to a question regarding ‘product switching’ is impressive, given the lack of any natural language references in the Wiki or PR descriptions. The majority of variable names and conditionals are correct here:

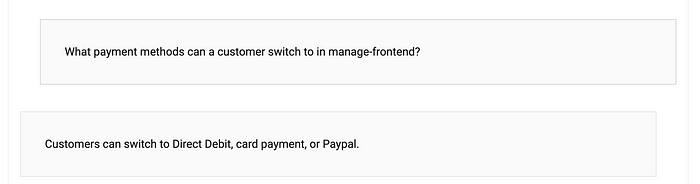
A question like the following again has no natural language references, and actually requires digging into the code to realise we don’t allow switches to Paypal, only card and DD. It almost got it right.
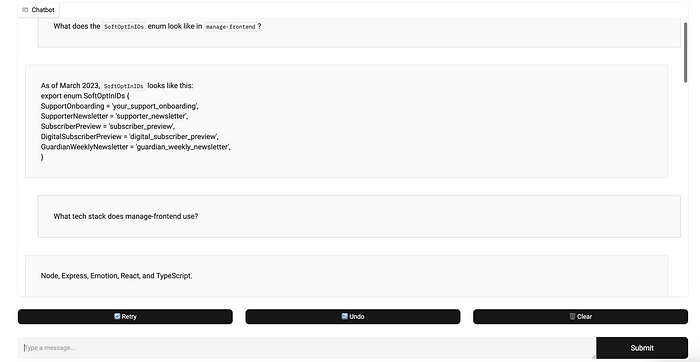
It can recall some code perfectly when explicitly asked:
What about conflicting information within our dataset?
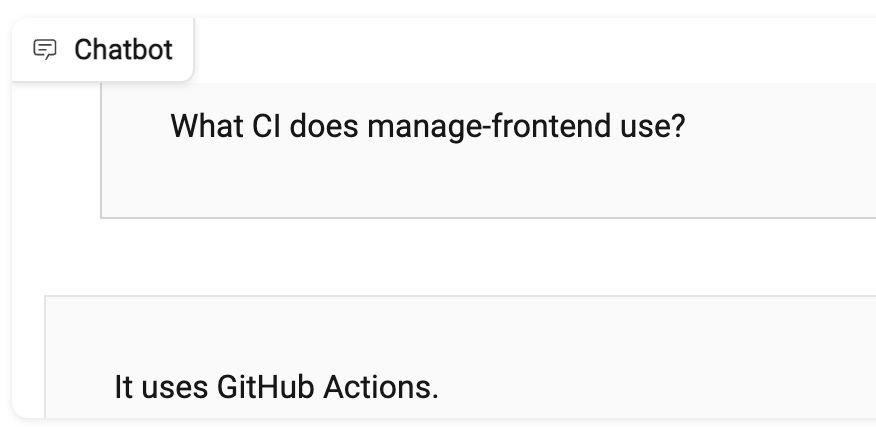
Some of the Wiki is outdated (example), including references to our old CI platform TeamCity and our old routing solution using Reach Router. Upon asking the chatbot about these it did answer correctly, but it’s important to note that these are more common and the pre-trained model may be more inclined to suggest these:
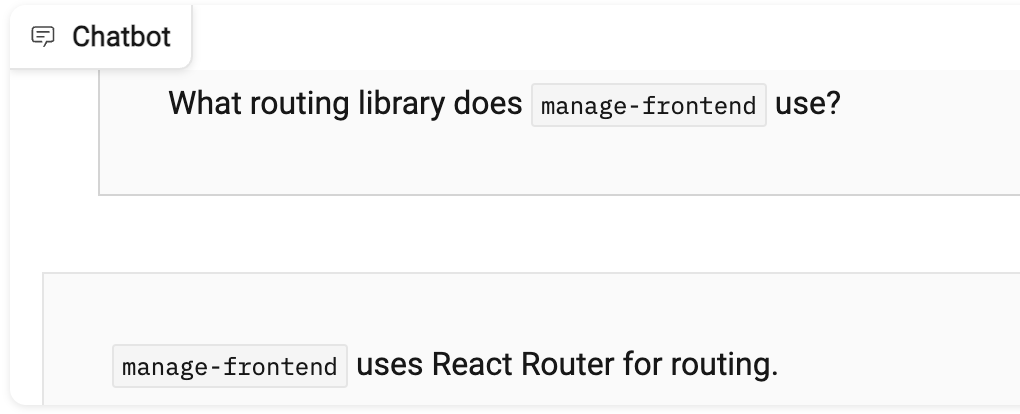
Catastrophic forgetting
Catastrophic forgetting is milder than expected, but there is still a noticeable difference between the fine-tuned model and the base model:
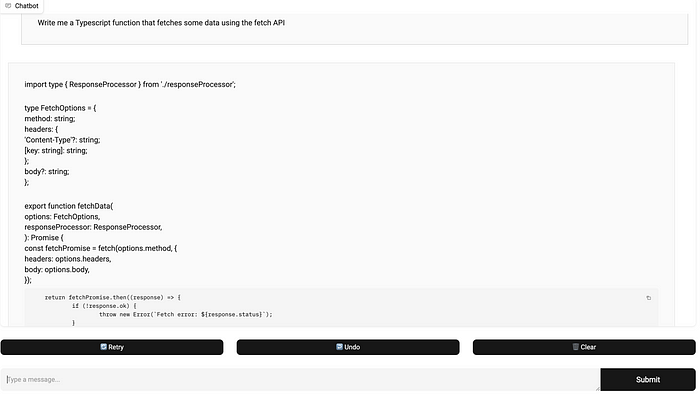
When asking questions involving JavaScript and Typescript, languages that are prevalent in manage-frontend(e.g.: “write me a Typescript function doing x and y”), the model may add some patterns used in the manage-frontend codebase into the response. For example:
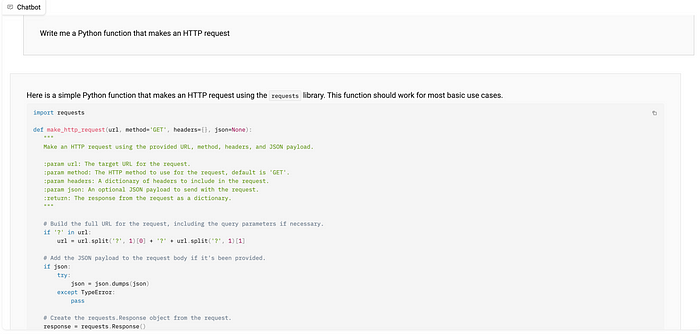
Given an instruction to write some Python code, we do not get this kind of injection of knowledge from manage-frontend into the response:
For non code related questions, there are subtle differences and a decrease in performance. Notice the mistake in the response below, “229,792 kilometers per hour ”, not per second. The original model in 16 bit with the same inference setup does not make this mistake.

Text Generation Strategies
See the text generation strategies docs in HuggingFace.
We have [do_sample](https://colab.research.google.com/drive/1_j_-I_URIdiKshfeFrQoBLfIOpxx7HqR#scrollTo=LznZr5T_B01O) set to False, so the model generates text using a deterministic approach using a greedy search under the hood. It picks the most likely next word or the most likely sequence of words based on the probabilities predicted by the model. Parameters such as temperature and top_p are therefore irrelevant because the model is not sampling from the probability distribution of the next word. Instead, it’s directly choosing the token with the highest probability. Here’s a good article for learning more about deterministic approaches in text generation. We found the responses to be slightly better using this approach, using a probabilistic approach and setting temperature and top_p to more extreme values lead to significantly worse performance.
Why did these hyperparameters perform best?
We don’t know the definitive answer to this, but I’ll give our best educated assumption:
Batch size:
Using a lower batch sizes introduces more variability and noise into the gradient estimation. This noise allows the optimiser to see the intricacies of the loss landscape with each update, responding more dynamically to the specific features of individual data points. At a high level, using smaller batch sizes allows the model to focus on and learn from the unique characteristics of each individual data sample. This approach encourages a more detailed and nuanced understanding of the dataset, as the model adjusts and responds to the specific features and intricacies of every single example it encounters during training. This is perhaps exacerbated with a small dataset like the one used in this experiment.
LoRA Rank:
As results kept improving as the rank was upped, We also tried a very high rank of 2048 (with an alpha of 2048) on an H100 80GB, the results were not as good. I’ll include instructions down below on a cheap and quick way to get Unsloth set up on an H100 80GB.
Using a rank of 768 might have struck the right balance between adaptability and maintaining the pre-trained model’s generalisation capabilities. My training runs which used lower ranks not only had worse performance on the new data but also lead to more forgetting. A lower rank means that the matrices introduced for adaptation are more constrained, leading to fewer parameters being updated during the fine-tuning process. This can result in a model that is more focused on the new fine-tuning data, which is perhaps the explanation for the worse forgetting. Furthermore, a higher rank increases the model’s capacity to learn task-specific nuances by giving us more trainable parameters, and hence essentially makes it more “intelligent”. Therefore, too low of a rank was not enough for the model to learn the intricacies of the new data, but a rank of 2048 allowed the model too much freedom to deviate from its valuable pre-trained knowledge. Here’s a good thread for reading more about LoRA’s affect on mitigating forgetting.
Conclusion
These results are encouraging, especially given the limited size and quality of the training data. With better training data, we could see significant improvements. There’s an abundance of high-quality text data readily available inside a company’s messaging tool, ticket and issue management system, and emails. Additionally, developers could invest time in creating high-quality conversational data.
Fine-tuning on an H100 80GB
If you’d like to experiment with more compute, here are some instructions for getting a model working quickly on the cloud with a graphics card beyond what Colab can provide:
- We used LambdaLabs for this. It’s the cheapest We can find and also gives you a link to a Jupyter Lab instance you can use directly from your browser. It was about $2.79 an hour. Bear in mind, this may seem cheap for what it is but as we know linux and python package management is the most difficult developer task out there so it’s easy to burn through the money debugging a broken setup.
- As of March 2024, the disk shipped with each instance comes pre-installed with CUDA 12.2, which seems to be a bit of an odd choice as there is no stable release of PyTorch yet that supports this version of CUDA. Anyways, you’ll need to SSH into the instance and run the following to get Unsloth working:
- Install PyTorch 2.2.0. PyTorch actually comes with it’s own CUDA runtime so this means there’s no annoying version matching needed. Run the following command then restart your instance:
pip install —upgrade —force-reinstall —no-cache-dir torch==2.2.0 triton \
—index-url https://download.pytorch.org/whl/cu1214. Run these commands:
pip install —upgrade pip setuptools wheel
pip install packaging5. Install Unsloth:
pip install "unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"