

Constructing ChatGPT
The established approach currently is as follows:
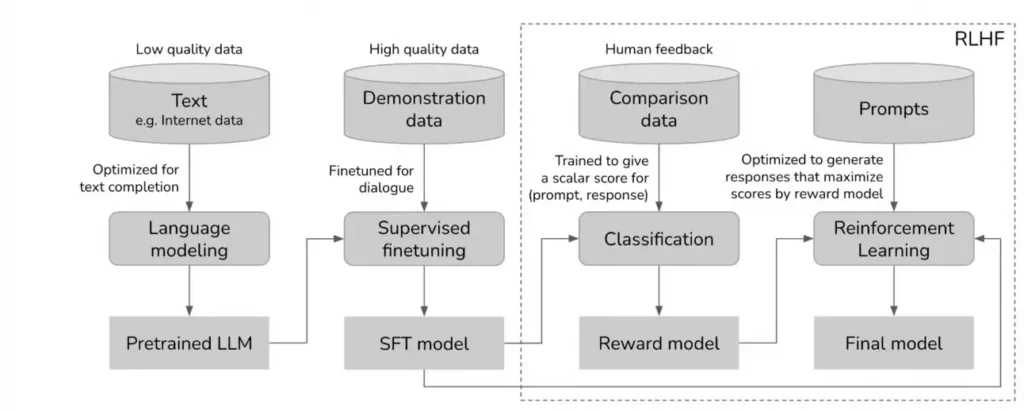
Source: Chip Huyen
Initially, you gather trillions of words from billions of documents, and through a self-supervised process, you prompt the model to forecast the subsequent token (word or sub-word) in a given sequence.
Subsequently, you aim to instruct the model to act in a specific manner, such as responding to queries upon request.
This leads us to phase 2, where we compile a dataset in which the model undertakes the same task, but within a structured, dialogue-oriented framework, transforming it into what we term assistants.
But our goal isn’t just to modify the model’s behavior; we also strive to enhance the reliability and safety of its outputs.
R einforcement L earning from H uman F eedback, or RLHF, through phases 3 and 4, achieves precisely this by guiding the model to not only respond as anticipated but also to deliver the most appropriate and secure response in alignment with human preferences.
Nonetheless, this presents an issue.
The Cost Dilemma
Simply put, RLHF is exceedingly costly.
It comprises three phases:
- Creating a preference dataset. By prompting the model in phase 2, a dataset of {prompt, response 1, response 2} is created, where a collective of humans judges which response, 1 or 2, is superior.
- Developing a reward model. In the third phase of the diagram above, a model is constructed to predict how effective each new response is. As one might guess, this model is trained using the preference dataset, by educating it to assign a higher score to the favored response from each pair.
- Reward Maximization. Ultimately, in diagram phase 4, the model is trained to optimize the reward. In essence, we instruct our model through a policy that learns to acquire the highest rewards from the reward model. Since this model embodies human preferences, we are implicitly aligning our model with those human preferences.
In simpler terms, you’re training a model to discover the ideal policy that learns to select the best action, in this case, word prediction, for every presented text.
Think of a policy as a framework for decision-making, where the model learns to select the best action (word prediction) for a given state (prompt).
And this results in ChatGPT. And Claude. And Gemini. However, with RLHF, the expenses become significant.
While the initial two phases before RLHF already demand millions of dollars, RLHF is just unaffordable for most of the global research community, because:
- It necessitates the creation of a highly refined dataset that requires extensive model prompting and the involvement of costly human experts.
- It demands the development of a completely new model, the reward model. This model is often as large and as capable as the model being aligned, doubling the computational costs.
- And it requires the execution of both the soon-to-be-aligned model and the reward model in a cyclic Reinforcement Learning training process.
Simply put, unless your name is Microsoft, Anthropic, Google, or a few others, RLFH is beyond reach.
But DPO alters this scenario.
Simplicity is Key
Direct Preference Optimization (DPO) is a groundbreaking mathematical innovation that aligns the trained model with human preferences without necessitating a Reinforcement Learning cycle.
That is, you optimize against an implicit reward without needing to explicitly materialize that reward. Without the necessity of materializing a reward model.
But before diving into what exactly that means, let’s revisit how models learn.
The Essence of Trial and Error
Fundamentally, all neural networks, whether ChatGPT or Stable Diffusion, are trained using backpropagation.
In essence, it’s essentially sophisticated trial and error.
A computable loss is defined, indicating how incorrect the model’s prediction is, and you utilize basic calculus to adjust the model’s parameters to gradually reduce that loss using partial derivatives.
Considering ChatGPT and its task of predicting the next token, since we know what the predicted word should be during training, our loss function is calculated based on the probability the model assigns to the correct word out of its entire vocabulary.
For example, if the next word is expected to be “Cafe” and the model has only given a 10% probability to that word, the loss is significant.
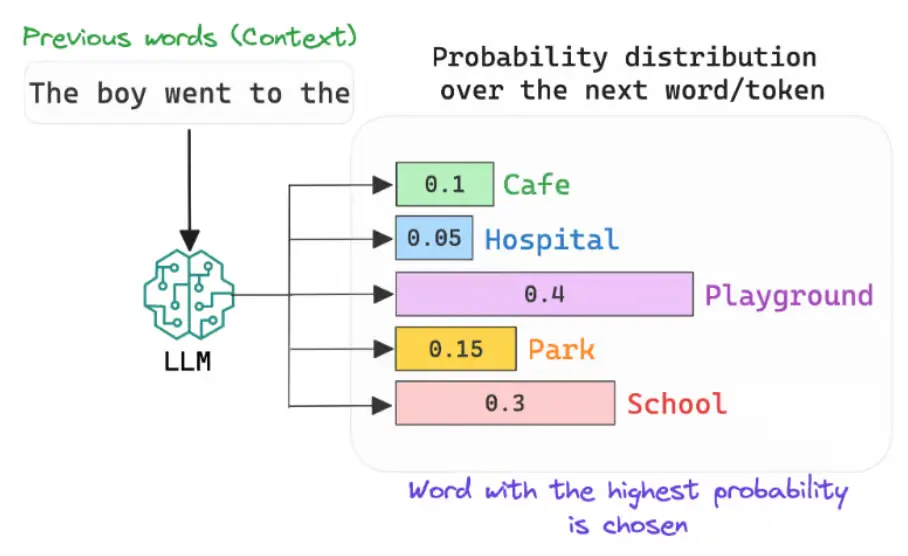
Source: @akshar_pachaar (X.com)
As a result, the model gradually learns to assign the highest probability to the correct word, thus effectively modeling language.
Therefore, in the previously mentioned four-step diagram, the model learns as just explained in steps 1 and 2, and in the case of RLHF, the loss function essentially instructs the model to maximize the reward.
Specifically, the RLHF loss function appears as follows:
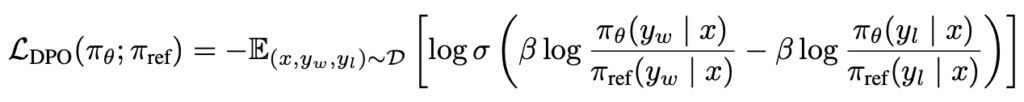
where the initial term r(x,y) determines the reward provided by the reward model.
And what about the term subtracting the reward?
The RLHF loss function also integrates a regularization component to prevent the model from diverging significantly from the original model.
So, how does DPO differ from RLHF?
The Rescue by Algebra
Crucially, DPO does not require a new model—the reward model—to execute the alignment process, unlike RLHF.
In essence, the Language Model you’re training secretly doubles as its own reward model.
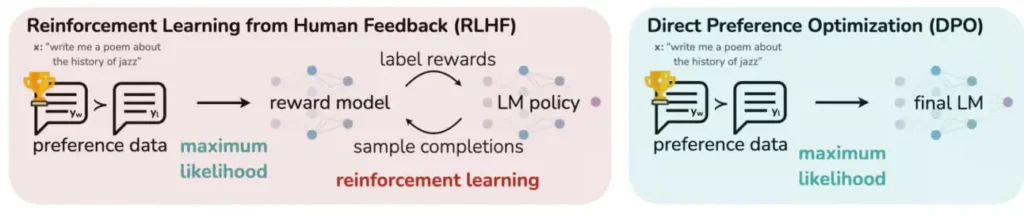
Source: Stanford
Utilizing ingenious algebra and grounded in the Bradley-Terry preference model—a probabilistic framework primarily predicting the outcomes of pairwise comparisons—they implicitly define the reward and directly train the LLM without the need for an explicit reward model.
While the DPO paper provides the detailed mathematical methodology, the core principle is that the procedure transitions from:
- Training an LLM » establish a preference dataset » develop a reward model » train the LLM to discover the policy that maximizes the reward, to:
- Training an LLM » establish a preference dataset » train the LLM to discover the policy.
How is the reward computed in DPO?
Intriguingly, the reward is implicitly integrated as part of the optimal policy.
In essence, what DPO demonstrates is that, when utilizing a human preference dataset, there’s no need to initially create a reward model to predict human choices and then use this model to optimize our target model.
Actually, we can identify the policy that aligns with our model without calculating the reward explicitly, because the optimal policy functions as a reward indicator, implying that by identifying that policy, we are implicitly maximizing the reward.
To put it simply, DPO can be viewed as a sophisticated algebraic shortcut that bypasses the explicit calculation of the reward by directly identifying the policy that implicitly maximizes the reward.
This introduces the following loss function:
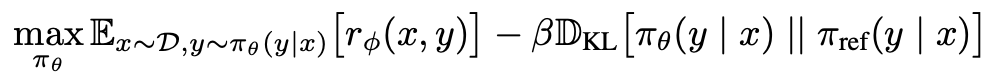
Where yw and yl represent the winning and losing responses in a specific comparison.
The logic is that the greater the probability the policy assigns to the preferred response and the lesser the probability given to the losing response, the smaller the loss.
The Year 2024: A Focus on Efficiency
We’re not even through the first month of the year, yet we’ve already witnessed the transformation of one of the most challenging, expensive, yet crucial steps in the development of our finest models.
Unquestionably, DPO democratizes the field, enabling academic institutions and smaller research laboratories to create models aligned with significantly reduced expenses.
The open-source community now possesses the capability to generate well-aligned models, rendering open-source models more attractive to corporations than ever before.
🫡 Principal Contributions 🫡
- DPO offers a sophisticated method for model alignment with human preferences in an economical manner, dismantling the barriers previously held by private entities in the alignment domain.
- The open-source community is now equipped with the means to develop well-aligned models, enhancing the attractiveness of open-source models to businesses more than ever.