
Jamba: A Groundbreaking AI Model by AI21 Labs
AI21 Labs, an AI research and product company focused on revolutionizing how humans read and write with AI assistance, has unveiled Jamba, a groundbreaking large language model (LLM) [3]. Jamba is the world’s first production-grade model built on the Mamba architecture.
What is Jamba?
Jamba boasts a 256K context window, allowing it to consider a vast amount of preceding information when processing a task. This extended context window is particularly beneficial for tasks requiring a deep understanding of a conversation or passage.
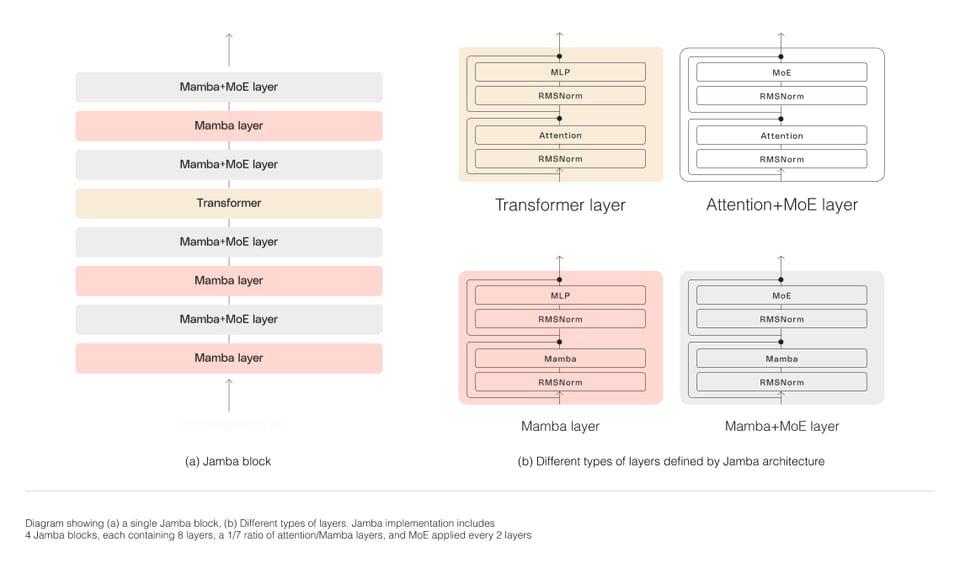
Jamba’s architecture is what truly sets it apart from other large language models. It combines two powerful approaches:
- Transformers: This widely used architecture excels at tasks like text generation and translation. Transformers analyze relationships between words, but can struggle with very long sequences of information.
- Mamba’s Structured State Space Model (SSM): This architecture is known for its ability to handle lengthy information streams efficiently. However, it may not be as effective as Transformers for specific tasks requiring intricate understanding of connections between words.
Jamba bridges this gap by cleverly merging these two architectures. Here’s the key element:
- Blocks and Layers: Jamba is built on a “blocks and layers” approach. Each block contains either an attention layer (based on the Transformer architecture) or a Mamba layer. This is followed by a multi-layer perceptron (MLP). Interestingly, Jamba uses a ratio of one attention layer for every eight total layers, prioritizing Mamba’s efficiency for most processing.
This unique combination allows Jamba to:
- Handle Long Contexts: By incorporating Mamba’s strength, Jamba can consider a vast amount of preceding information (256K context window) when processing a task.
- Maintain Efficiency: The focus on Mamba layers keeps Jamba computationally efficient, making it faster and more cost-effective to run compared to Transformer-only models of similar size.
Overall, Jamba’s architecture represents a significant leap forward in LLM design, offering exceptional throughput, superior performance, and cost-effective deployment for tasks involving lengthy contexts.
Key Features of Jamba
- Unprecedented Throughput: Jamba delivers 3x higher throughput on long contexts compared to other models in its size class. This translates to faster processing times, making it the most efficient model of its kind for tasks involving lengthy sequences.
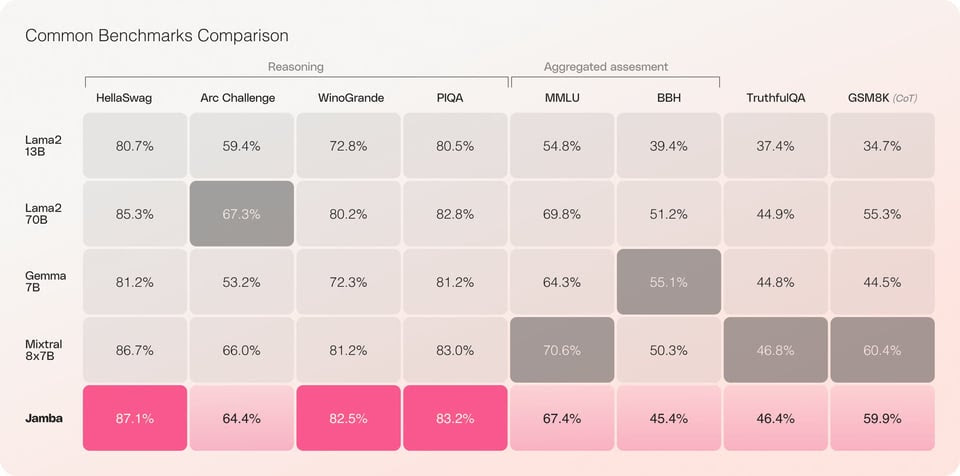
- Superior Performance: Jamba performs exceptionally well on various benchmarks, either surpassing or matching other state-of-the-art models in its size category. Notably, it excels in reasoning-related tasks, demonstrating a strong ability to understand and analyze complex relationships within information.
- Cost-Effective Deployment: Jamba is designed to be cost-effective. It’s the only model of its size that can fit a 140K context on a single GPU, reducing hardware requirements and making it more accessible for deployment.
- Open Model for Experimentation: Jamba is released as an open-source model under the Apache 2.0 license, allowing researchers and developers to freely experiment, build upon it, and create custom solutions.
Who can benefit from Jamba?
Jamba is a powerful foundation for various applications, particularly those that require exceptional efficiency when dealing with lengthy contexts. Here are some potential use cases:
- Advanced Chatbots: Jamba’s ability to handle long conversations and remember past interactions makes it ideal for building chatbots that can provide more comprehensive and natural interactions.
- Machine Translation: Jamba’s deep context understanding can improve the accuracy and fluency of machine translation, especially for complex documents or nuanced communication.
- Text Summarization: Jamba can effectively summarize lengthy pieces of text while retaining key information and context, making it valuable for tasks like generating concise reports or summaries of research papers.
Jamba is still under development, with a safer, fine-tuned version expected to be released soon. However, the initial release demonstrates its potential to revolutionize how we interact with AI and process information.
Note: While the provided transcripts mention availability on platforms like Hugging Face and the AI21 Platform, this information is subject to change. It’s advisable to refer to the official AI21 Labs website for the latest access instructions.
Checkout more model summary like this here