

As larger models require pretraining on trillions of tokens, it is unclear how scalable is curation of “high-quality” corpora, such as social media conversations, books, or technical papers, and whether we will run out of unique high-quality data soon.
Falcon shows that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. An extract of 600 billion tokens from the REFINEDWEB dataset and 1.3/7.5B parameters language models trained on it are publicly released.
Macrodata Refinement and RefinedWeb
MDR (MacroData Refinement), a pipeline for filtering and deduplicating web data from CommonCrawl at a very large scale is used to produce RefinedWeb
Design principles
- Scale First: MDR is intended to produce datasets to be used to train 40–200B parameters models, thus requiring trillions of tokens.
- Strict deduplication: Both exact and fuzzy deduplication are combined, and strict settings are used, resulting in removal rates far higher than those reported by others.
- Neutral filtering: To avoid introducing further undesirable biases into the model, ML-based filtering outside of language identification is avoided. Simple rules and heuristics and only URL filtering for adult content are used.
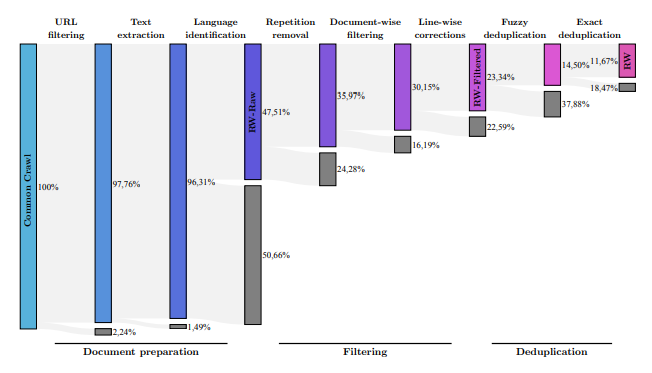
Subsequent stages of Macrodata Refinement remove nearly 90% of the documents originally in CommonCrawl.
Document Preparation
- URL filtering: A first filtering based on the URL is performed. This targets fraudulent and/or adult websites. The filtering is based on two rules: (1) an aggregated blocklist of 4.6M domains; (2) a URL score, based on the presence of words from a list curated and weighed by severity.
- Text extraction: trafilatura is used to extract only the main content of the page, ignoring menus, headers, footers, and ads among others. Extra formatting via regular expressions is applied. New lines are limited to two consecutive ones, and all URLs are removed.
- Language identification: fastText language classifier of CCNet is used at the document level, documents for which the top language scores below 0.65 are removed as this usually corresponds to pages without any natural text.
Filtering
- Document-wise filtering: A significant fraction of pages are machine-generated spam, made predominantly of lists of keywords, boilerplate text, or sequences of special characters. Such documents are not suitable for language modeling; to filter them out, we adopt the quality filtering heuristics. These focus on removing outliers in terms of overall length, symbol-to-word ratio, and other criteria ensuring the document is actual natural language.
- Line-wise corrections: A line-correction filter, targeting undesirable items (e.g., social media counters 3 likes, navigation buttons) is devised. If these corrections remove more than 5% of a document, it is removed entirely.
Deduplication
- Fuzzy deduplication: Similar documents are removed by applying MinHash for each document, a sketch is computed, and its approximate similarity with other documents is measured, eventually removing pairs with high overlap. Templated documents are efficiently identified by MinHash.
- Exact deduplication: Exact substring operates at the sequence level instead of the document level, finding matches between strings that are exact token-by-token matches by using a suffix array. Any match of more than 50 consecutive tokens is removed.
- URL deduplication: CommonCrawl dumps exhibited significant overlap, with URLs being revisited across dumps despite no change in content. Consequently, a list of the URLs from each part that had been retained is maintained, and they are removed from subsequent parts being processed.
Experiments
Evaluation is based on the popular Eleuther AI evaluation harness, allowing evaluation across a wide range of tasks in the zero-shot setting.
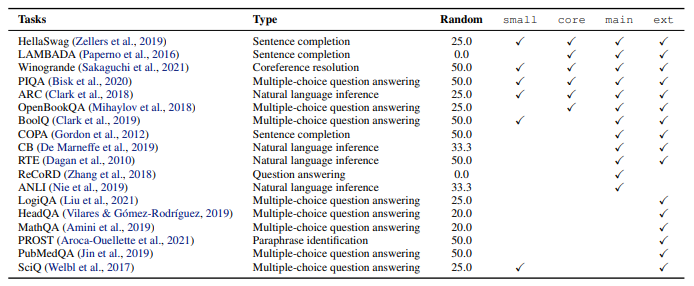
To evaluate models trained on RefinedWeb and compare to the state-of-the-art, Four aggregates are built across 18 tasks on which to measure zero-shot performance.
- small was built for internal ablations, based on tasks with consistent performance at a small scale
- core is based on tasks commonly reported for public suites of models
- main is based on tasks from the GPT-3 and PaLM paper
- ext is based on tasks used by the BigScience Architecture and Scaling group
For all reported results, † is used to denote results obtained in an arbitrary evaluation setup and ∗ is used to denote results obtained using the EAI Harness, which is also employed for all our models.
Autoregressive decoder-only models with 1B, 3B, and 7B parameters are trained, based on configurations and hyperparameters similar to those of GPT-3, with the main divergence being the use of ALiBi and FlashAttention.
Findings
Can web data alone outperform curated corpora? Challenging existing beliefs on data quality and LLMs, models trained on adequately filtered and deduplicated web data alone can match the performance of models trained on curated data.

Curation is not a silver bullet for zero-shot generalization: small-scale models trained on REFINEDWEB outperform models trained on web data (C4, OSCAR), and on curated corpora (The Pile)
Average accuracy in zero-shot on the small-agg aggregate. All models were trained with identical architectures and pretraining hyperparameters.
OSCAR-22.01 underperforms other datasets significantly, perhaps because deduplication is only optional. C4 is a strong baseline, with OSCAR-21.09 lagging slightly behind.
RefinedWeb outperforms both web datasets and the most popular curated dataset, The Pile. Both filtering and deduplication contribute significantly to improving zero-shot performance.
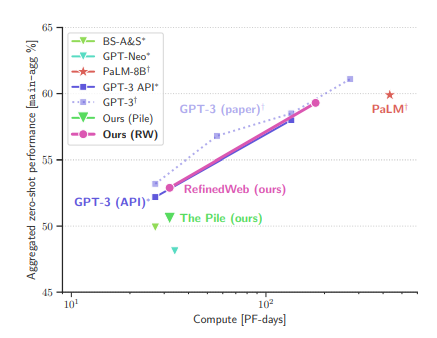
Models trained on REFINEDWEB alone outperform models trained on curated corpora.
Zero-shot performance on main-agg task aggregate.
At equivalent compute budgets, Falcon models significantly outperform publicly available models trained on The Pile, and match the performance of the GPT-3 models when tested within our evaluation setup.
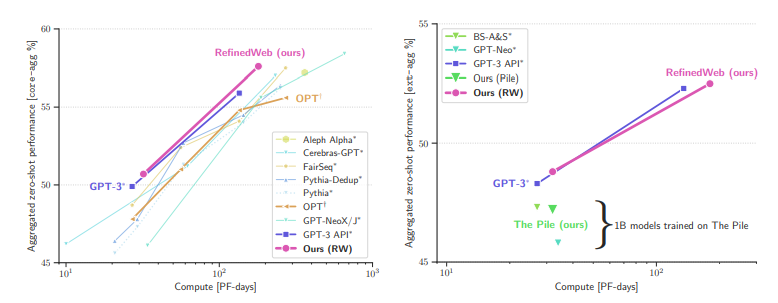
Models trained on REFINEDWEB alone outperform models trained on curated corpora.
Zero-shot performance averaged on core-agg (left) and ext-agg (right) task aggregates.
Existing open models fail to match the performance of the original GPT-3 series (left); however, models trained on RefinedWeb significantly outperform models trained on The Pile: including our direct comparison model (right), ruling out our pretraining setup as the main source of increased performance.
In fact, RefinedWeb models even match the performance of the GPT-3 models.
Do other corpora benefit from MDR? While filtering heuristics may require source-dependent tuning, stringent deduplication improves zero-shot performance across datasets consistently.
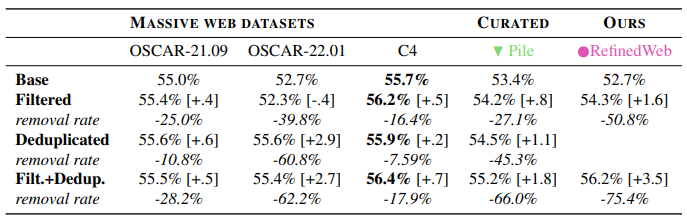
Although improvements from filtering are not systematic across datasets, deduplication brings a steady performance boost across the board.
Zero-shot accuracy averaged on our small-agg aggregate; [+x.x] reports absolute gains compared to the base, removal rates reported against the base. Due to limitations in our pipeline, we cannot apply the deduplication stage independently for RefinedWeb.
Limitations
A basic analysis of the toxicity of RefinedWeb is conducted. RW is about as toxic as The Pile, based on the definition of toxicity provided by the Perspective API
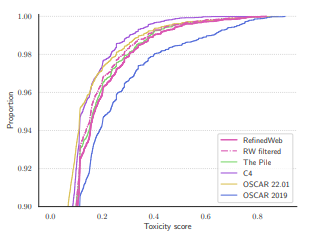
Toxic content in RefinedWeb is distributed similarly to The Pile. Cumulative proportion of documents below a given toxicity score, as evaluated by the Pespective API.
Paper
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only 2306.01116