

GPT-NeoX-20B is an autoregressive language model trained on the Pile, and the largest dense autoregressive model that had publicly available weights at the time of submission.
Model Architecture
GPT-NeoX-20B’s architecture largely follows that of GPT-3 with a few notable deviations. It has 44 layers, a hidden dimension size of 6144, and 64 heads.
Rotary Positional Embeddings
Instead of the learned positional embeddings as used in GPT models, Rotary Positional Embeddings are used. RPE is applied only to the first 25% of embedding vector dimensions in order to strike a balance of performance and computational efficiency.
Parallel Attention + FF Layers
The Attention and Feed-Forward (FF) layers are computed in parallel, and the results are summed instead of being run in series for improved efficiency.
Due to an oversight in the code, two independent Layer Norms are applied instead of using a tied layer norm. Instead of computing:
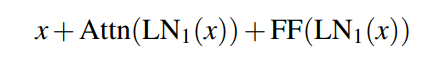
as intended, the codebase unties the layer norms:
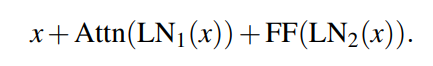
Initialization
For the Feed-Forward output layers before the residual 2/L * sqrt(d)initialization scheme is used as it prevents activations from growing with increasing depth and width, and the factor of 2 compensates for the fact that the parallel and feed-forward layers are organized in parallel.
For all other layers,the small init scheme sqrt(2/d+4d) is used.
All Dense Layers
While GPT-3 uses alternating dense and sparse layers, only dense layers are used to reduce implementation complexity.
Training Data
GPT-NeoX-20B was trained on the Pile as-is i.e. without any deduplication. The Pile is a massive curated dataset (over 825 GiB) designed specifically for training large language models. It consists of data from 22 data sources, coarsely broken down into 5 categories:
- Academic Writing : Pubmed Abstracts and PubMed Central, arXiv, FreeLaw, USPTO Backgrounds, PhilPapers, NIH Exporter.
- Web-scrapes and Internet Resources : CommonCrawl, OpenWebText2, StackExchange, Wikipedia (English).
- Prose : BookCorpus2, Bibliotik, Project Gutenberg.
- Dialogue : Youtube subtitles, Ubuntu IRC, OpenSubtitles, Hacker News, EuroParl.
- Miscellaneous : GitHub, the DeepMind Mathematics dataset, Enron Emails.
Tokenization

GPT-2 tokenization vs. GPT-NeoX-20B tokenization.
A BPE-based tokenizer similar to that of GPT-2 is employed for GPT-NeoX-20B, with the same total vocabulary size of 50257, With three major changes.
- The tokenizer is trained based on the Pile, making use of its diverse text sources to construct a more general-purpose tokenizer.
- In contrast to the GPT-2 tokenizer, where tokenization at the start of a string is treated as a non-space-delimited token, consistent space delimitation is applied.
- Tokens for repeated space tokens (all positive integer amounts of repeated spaces up to and including 24) are included in our tokenizer. This allows text with large amounts of whitespace to be tokenized using fewer tokens.
Evaluation
The model’s evaluation is done using the EleutherAI Language Model Evaluation Harness, which supports various model APIs.
Natural Language Tasks

Zero-shot performance on a variety of language modeling benchmarks.
- Outperforms FairSeq 13B on some tasks (e.g., ARC, LAMBADA, PIQA, PROST).
- Underperforms on other tasks (e.g., HellaSwag, LogiQA zeroshot).
- Across 32 evaluations: Outperforms on 22 tasks, underperforms on 4, and falls within the margin of error on 6.
- Weakest performance on HellaSwag, scoring four standard deviations below FairSeq 13B in both zero- and five-shot evaluations.
- GPT-J also underperforms FairSeq 6.7B by three standard deviations zero-shot and six standard deviations five-shot on HellaSwag.
Mathematics
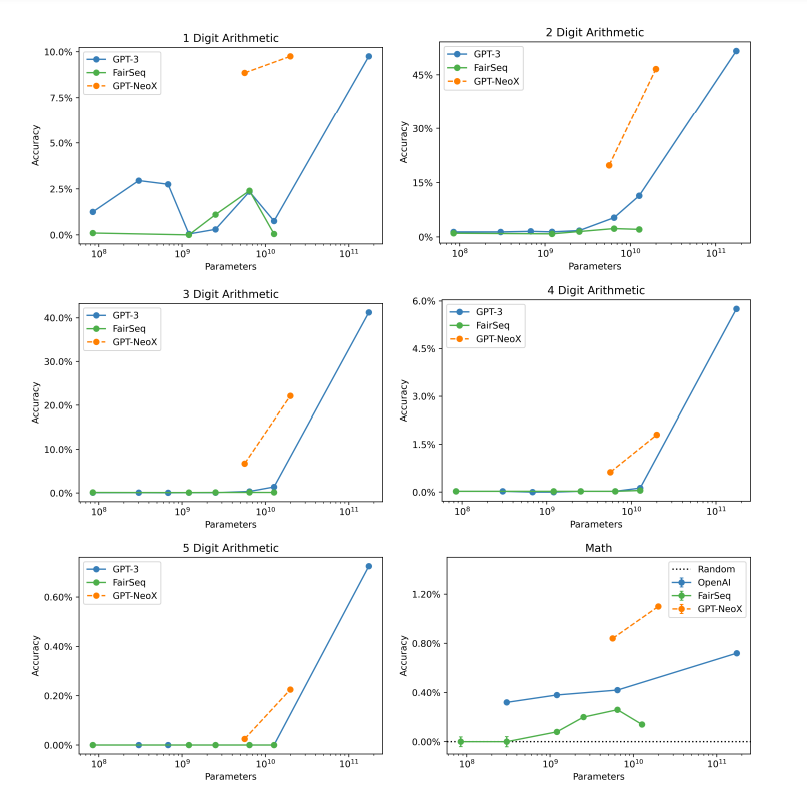
Zero-shot performance on arithmetic tasks and MATH.
- GPT-3 and FairSeq models are generally close on arithmetic tasks.
- GPT-J and GPT-NeoX consistently outperform them.
- The reason is attributed to the prevalence of mathematics equations in the training data.
- Training on the Pile doesn’t necessarily produce better out-of-distribution arithmetic reasoning.
Advanced Knowledge-Based Tasks
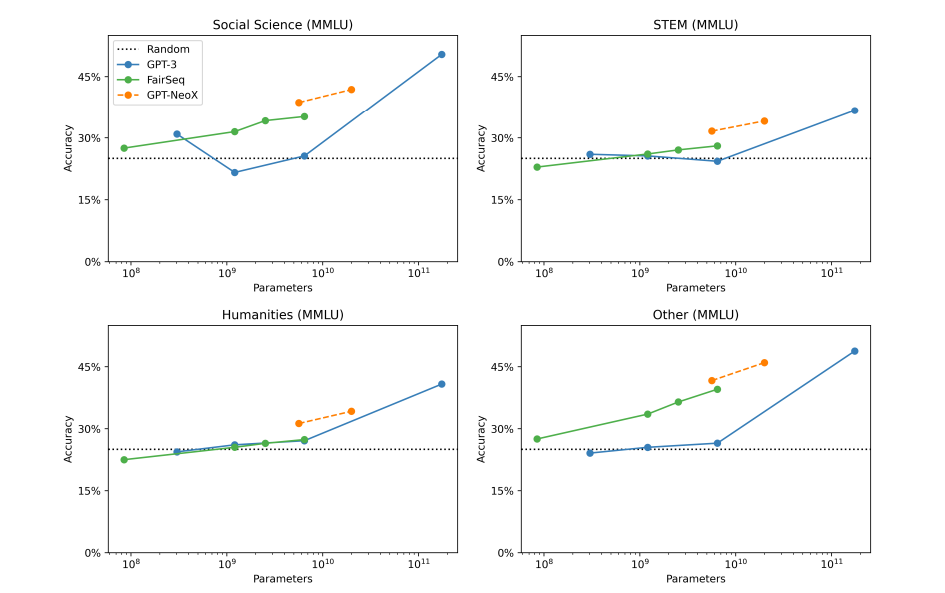
Five-shot performance on MMMLU
- GPT-NeoX and FairSeq models perform dominantly on MMMLU compared to GPT-3 in the five-shot setting.
- Performance is closer in the zero-shot setting.
- Contrasts with a study that claimed few-shot evaluation doesn’t improve performance, as GPT-NeoX and FairSeq models substantially improve with as few as five examples.
- Emphasizes the importance of using multiple models in evaluation benchmarks to avoid overfitting conclusions to a specific model.
Paper
GPT-NeoX-20B: An Open-Source Autoregressive Language Model 2204.06745