

Mistral 7B is an LLM engineered for superior performance and efficiency. It leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost.
Mistral 7B outperforms the best open 13B model (Llama 2) across all evaluated benchmarks, and the best released 34B model (Llama 1) in reasoning, mathematics, and code generation.
Mistral 7B — Instruct, model fine-tuned to follow instructions on instruction datasets publicly available on the Hugging Face repository, surpasses Llama 2 13B — chat model both on human and automated benchmarks.
Architecture
Mistral 7B is based on a transformer architecture.
Compared to Llama, it introduces a few changes:
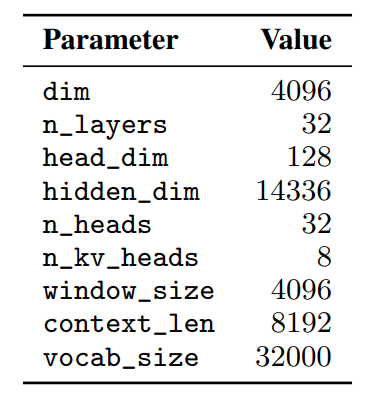
Sliding Window Attention
Sliding Window Attention leverages the layers of a transformer model to extend its attention beyond a fixed window size, denoted as W. In SWA, the hidden state at position i in layer k can attend to hidden states from the preceding layer within the range of positions i — W to i, allowing access to tokens at a distance of up to W * k tokens. By employing a window size of W = 4096, SWA theoretically achieves an attention span of approximately 131K tokens. In practice with a sequence length of 16K and W = 4096, SWA modifications in FlashAttention and xFormers result in a 2x speed enhancement compared to vanilla attention methods.
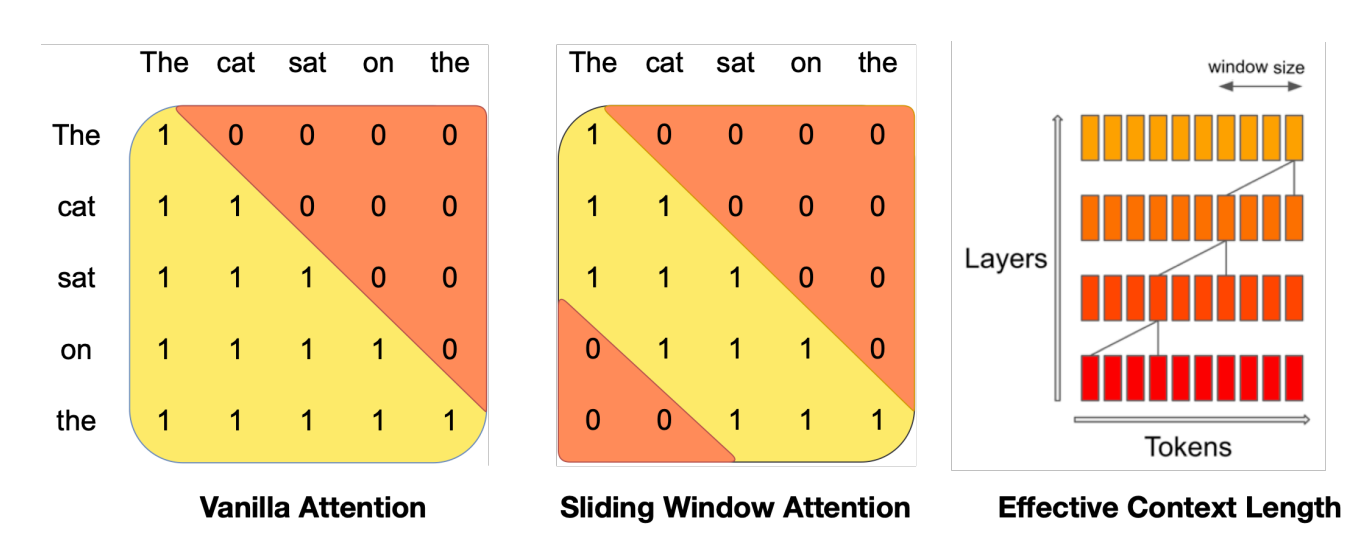
Rolling Buffer Cache

A Rolling Buffer Cache, employs a fixed attention span to limit cache size. The cache is of fixed size W, and it stores keys and values for timestep i at position i mod W in the cache. When i exceeds W, earlier values are overwritten, halting cache size growth. For instance, with W = 3, on a 32k-token sequence, cache memory usage is reduced by 8x without compromising model quality.
Pre-fill and chunking
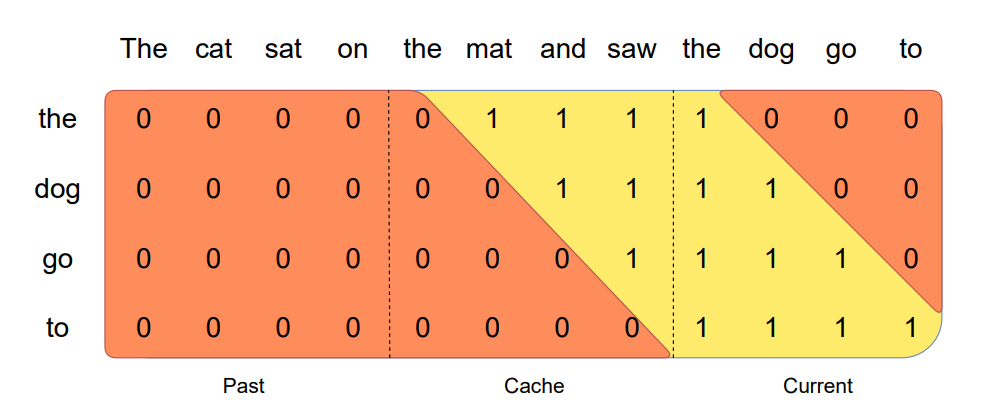
In sequence generation, tokens are predicted sequentially based on prior context. To optimize efficiency, a (k, v) cache is pre-filled with the known prompt. If the prompt is very long, it is chunked into smaller segments using a chosen window size. Each chunk is used to pre-fill the cache. This approach involves computing attention both within the cache and over the current chunk, Thus aiding in more effective sequence generation.
Results
Mistral is evaluated against the following benchmarks:
- Commonsense Reasoning (0-shot): Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, ARC-Easy, ARC-Challenge, CommonsenseQA
- World Knowledge (5-shot): NaturalQuestions, TriviaQA
- Reading Comprehension (0-shot): BoolQ, QuAC
- Math: GSM8K (8-shot) with maj@8 and MATH (4-shot) with maj@4
- Code: Humaneval (0-shot) and MBPP (3-shot)
- Popular aggregated results: MMLU (5-shot), BBH (3-shot), and AGI Eval (3–5-shot, English multiple-choice questions only)
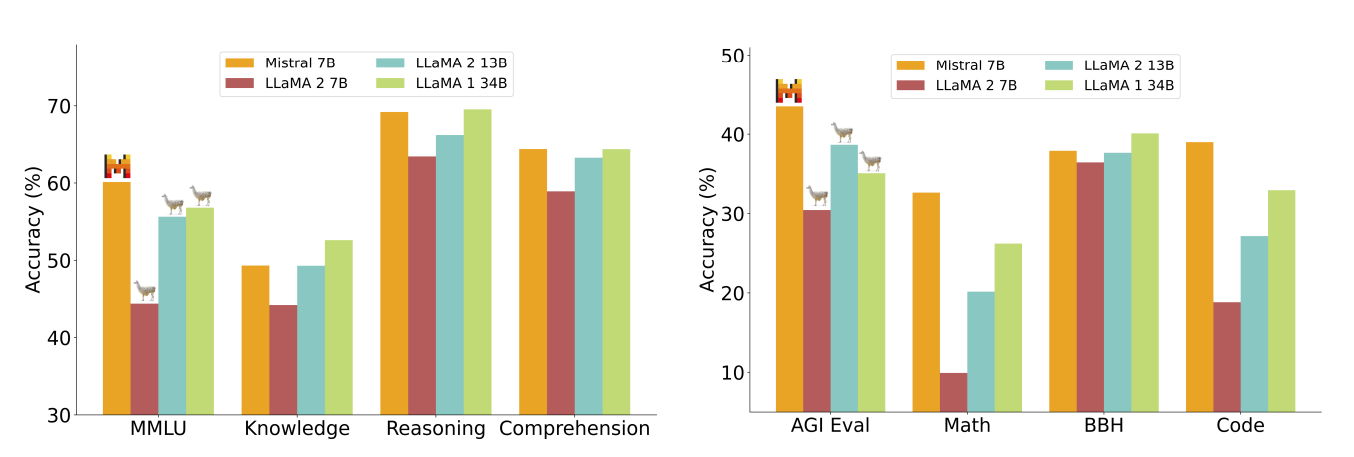
Performance of Mistral 7B and different Llama models on a wide range of benchmarks.

Comparison of Mistral 7B with Llama.
- Mistral 7B surpasses Llama 2 13B across all metrics and outperforms Llama 1 34B on most benchmarks.
- In particular, Mistral 7B displays superior performance in code, mathematics, and reasoning benchmarks.
Instruction Following

Comparison of Chat models.
- Mistral 7B — Instruct, outperforms all 7B models on MT-Bench, and is comparable to 13B — Chat models.
- In an independent human evaluation, conducted on https://llmboxing.com/leaderboard. The outputs generated by Mistral 7B were preferred 5020 times, compared to 4143 times for Llama 2 13B.
Paper
Mistral 7B 2310.06825