

Introduction
The R-squared metric — R², or the coefficient of determination – is an important tool in the world of machine learning. It is used to measure how well a model fits data, and how well it can predict future outcomes. Simply put, it tells you how much of the variation in your data can be explained by your model. The closer the R-squared value is to one, the better your model fits the data.
In this article, we will discuss what R squared is, the math behind this metric, where it is useful and where it is not useful. We’ll also look at some practical examples of using the R-squared metric in machine learning. By the end of this article, you should have a better understanding of when and why to use the R-squared metric as part of your machine learning models.
What Is R Squared
R-squared, also known as the coefficient of determination, is a statistical measure used in machine learning to evaluate the quality of a regression model. It measures how well the model fits the data by assessing the proportion of variance in the dependent variable explained by the independent variables.
R-squared indicates the percentage of variation in your target variable that can be explained by your independent variables. It measures how closely related each variable is to one another and how predictable each dependent variable is from its respective set of independent variables.
The R-squared value ranges from 0 to 1, with a value of 1 indicating a perfect fit of the model to the data, while a value of 0 indicates that the model does not explain any of the variability in the dependent variable.
A high R-squared value would usually indicate that the model explains a large proportion of the variability in the data, while a low R-squared value suggests that the model does not explain much of the variability.
How do you calculate the coefficient of determination?
The R-squared metric is a post-metric that is calculated using other metrics. R-squared is calculated mathematically by comparing the Sum of Squares of Errors (SSE) or the Sum of Squared Residuals (SSR) to the Total Sum of Squares (SST). Note: SSE and SSR can be used interchangeably.
R-squared can be calculated using the following formula:
R² = 1 – (SSE/SST)
SSE is the sum of the squared differences between the actual dependent variable values and the predicted values from the regression model. It represents the variability that is not explained by the independent variables.
SST is the total variation in the dependent variable and is calculated by summing the squared differences between each actual dependent variable value and the mean of all dependent variable values.
Once SSE and SST are calculated, R-squared is determined by dividing SSE by SST and then subtracting the result from 1. The resulting value represents the proportion of the total variation in the dependent variable that is explained by the independent variables.
To interpret an R-squared value, look at how close it is to 1. A value of 0 indicates that your model does not explain any of the variability of your data, while a value of 1 suggests that your model perfectly explains all of the variability in your data. Values between 0 and 1 suggest that your model is able to explain some variability in your data, but not all.
In order to decide whether or not a predictive model has been accurately fitted with an R-squared value, first consider other factors such as Mean Absolute Error (MAE) and Root Mean Square error (RMSE). Both MAE and RMSE are measures of how far off your predictions are from actual values. While they do not provide a measure of how well or poorly a model fits the data, they can be used in conjunction with R-squared to make an overall assessment of its quality.
By comparing different models with different coefficients and parameters, analysts can identify which model best fits their data by assessing its R-squared value. The higher the R-squared value, the more closely it matches observed data — thus making it a good indicator of how accurate a given model is in predicting future outcomes.
The R-squared value can also be calculated using software packages such as Python, R, or Excel.
In Python, R-squared can be computed from the Sci-kit learn library. Here’s an example:
from sklearn.metrics import r2_score
r2 = r2_score(y_test,y_pred)
print(f"R-squared value = {r2}")Limitations and Misconceptions of the Coefficient of Determination
While the R-squared metric is a useful tool for measuring the accuracy of a machine learning model, it has some limitations. One of the main drawbacks of R-squared is that it assumes that all variables in the model are independent, which is not always the case.
Another potential limitation or drawback is that the metric also has trouble detecting non-linear relationships and can give misleading results when working with smaller datasets.
Ultimately, R-squared is only one measure of accuracy – other metrics such as Mean Absolute Error or Root Mean Square Error may be more appropriate for certain contexts.
Several prominent misconceptions exist about R squared. The first is that a high value of R-squared implies that the regression model is useful for predicting new observations. However, this is not necessarily true, as R-squared only represents the proportion of variation in the sample data that is explained by the regression model, and may not accurately reflect the proportion of variation in the population that can be explained by the model. The accuracy of R-squared as an estimate of the population proportion is affected by the technique used to select terms for the model. If the selection process allows insignificant terms in the model, then R-squared may have a bias toward high values, leading to an overfitted model that does not generalize well to new observations from the population.
The second misconception is that a low value of R-squared implies that the regression model is not useful. However, this is not necessarily true either, as a low value of R-squared may reflect the exclusion of significant terms (Type II error) from the model. In this case, R-squared may have a bias toward low values, leading to an underfitted model that does not capture important relationships in the data.
Additionally, a higher R-squared value does not always equate to better predictions – as a rule of thumb, values over 0.8 should be treated with caution.
Ultimately, the best way to use and understand R-squared is to experiment with different models and compare the results. With practice and experience, you will soon become familiar with this powerful metric and be able to leverage it for robust machine learning solutions.
Adjusted R² Definition and Formula
The R-squared metric is not perfect, and it can be improved upon. This is where the adjusted R-squared metric comes in.
The adjusted R-squared takes into account the number of parameters used to calculate the model. It is calculated by subtracting the proportion of variance unaccounted for by the model, from 1 (the total variance in the data).
The formula for adjusted R-squared is:
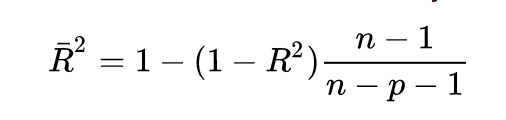
where n is the number of observations and p is the number of independent variables in the model.
The adjusted R-squared can be a better measure of predictive power than the R-squared because it penalizes additional parameters and reduces the overfitting of models to data. With an adjusted R-squared metric, more complex models are more likely to show lower scores, as more parameters will lead to an increase in variance that is not explained by the model, and thus a lower score.
This helps to identify models that have high predictive power without adding unnecessary parameters that do not contribute significantly to the explanation of variance in the data.
In Action: Comparing Regression Models
The R-squared metric and its more precise counterpart, the adjusted r-squared metric, allow you to easily compare regression models and determine which one performs better.
While the R-squared metric measures the proportion of variance in the dependent variable that can be explained by the independent variables, the adjusted R-squared compensates for additional independent variables by factoring in the ratio of observations to variables. The former is calculated by comparing the sum of squares of errors (SSE) to the total sum of squares (SST) and is expressed as a percentage. A higher number indicates a better fit of the model. The latter helps to determine whether adding more variables improves the model’s accuracy and if the increase in explanatory power justifies adding additional variables.
Both metrics are useful in gauging how well your regression models are performing so you can get an accurate representation of your data. By comparing multiple models side-by-side with both metrics, you can easily identify which model has a better fit and make informed decisions about how to use it for predictive analytics.
Where is R Squared Most and Least Useful?
R-squared is most useful in industries that rely on regression models, such as finance, economics, marketing, and engineering.
In finance, R-squared can be used to evaluate the performance of asset pricing models. In marketing, R-squared might be used to measure the effectiveness of advertising campaigns. In engineering, R-squared can be used to evaluate the accuracy of predictive maintenance models.
The advantage of using this metric lies in its ability to measure variability: it describes how much variation is explained by the model itself compared to the base case that could have been used. This makes it invaluable for determining whether an algorithm is performing accurately and efficiently, as well as for comparing two different algorithms’ performances side-by-side.
R-squared is not ideal when it comes to certain machine learning models such as those involving non-linear regression or time series prediction. Another metric called the root mean squared error (RMSE) might be used as an alternative in some cases. RMSE is a measure of model accuracy that takes into account the size of the errors in predictions made by a machine learning model. It measures the average of the difference between predicted and actual values and can be helpful for comparing machine learning models. Since it penalizes large errors much more than small errors, it allows for better differentiation between similarly performing models with large error values being less favored than those with smaller ones. This makes it an excellent metric for use in scenarios where the cost of incorrect prediction needs to be considered, such as predicting electricity demand.
Conclusion
R-squared metric is an important tool in the arsenal of machine learning models. It is especially useful when it comes to evaluating regression models, which make predictions of a continuous variable (like sales prices) from training data.