
The third generation of Llama models provided fine-tunes (Instruct) versions that excel in understanding and following instructions. However, these models are heavily censored, designed to refuse requests seen as harmful with responses such as “As an AI assistant, I cannot help you.” While this safety feature is crucial for preventing misuse, it limits the model’s flexibility and responsiveness.
In this article, we will explore a technique called “abliteration” that can uncensor any LLM without retraining. This technique effectively removes the model’s built-in refusal mechanism, allowing it to respond to all types of prompts.
The code is available on Google Colab and in the LLM Course on GitHub.
✂️ What is abliteration?
Modern LLMs are fine-tuned for safety and instruction-following, meaning they are trained to refuse harmful requests. In their blog post, Arditi et al. have shown that this refusal behavior is mediated by a specific direction in the model’s residual stream. If we prevent the model from representing this direction, it loses its ability to refuse requests. Conversely, adding this direction artificially can cause the model to refuse even harmless requests.
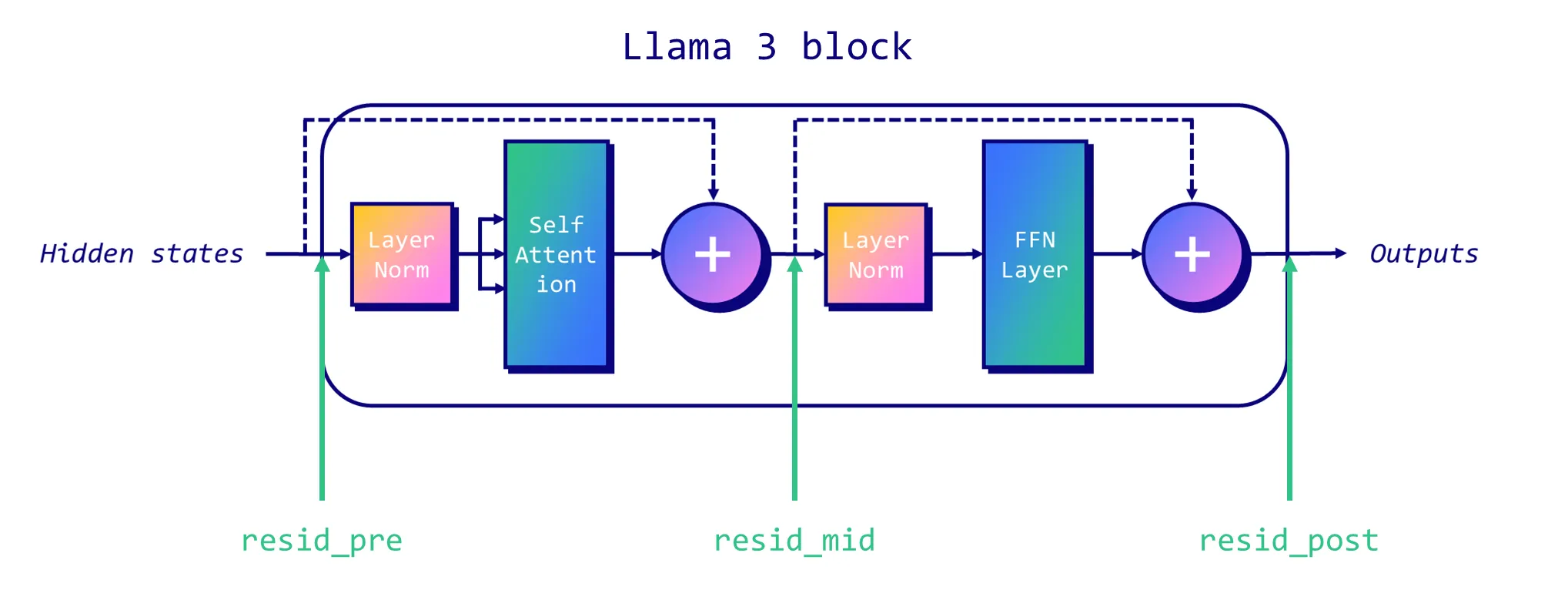
In the traditional decoder-only Llama-like architecture, there are three residual streams we can target: at the start of each block (“pre”), between the attention and MLP layers (“mid”), and after the MLP (“post”). The following figure illustrates the location of each residual stream.
To uncensor an LLM, we first need to identify the “refusal direction” within the model. This process involves a few technical steps:
Data Collection : Run the model on a set of harmful instructions and a set of harmless instructions, recording the residual stream activations at the last token position for each.
Mean difference : Calculate the mean difference between the activations of harmful and harmless instructions. This gives us a vector representing the “refusal direction” for each layer of the model.
Selection : Normalize these vectors and evaluate them to select the single best “refusal direction.”
Once we have identified the refusal direction, we can “ablate” it, effectively removing the model’s ability to represent this feature. This can be done through an inference-time intervention or permanently with weight orthogonalization.
Let’s talk about inference-time intervention first. For every component that writes to the residual stream (such as an attention head), we calculate the projection of its output onto the refusal direction and subtract this projection. This subtraction is applied at every token and every layer, ensuring that the model never represents the refusal direction.
On the other hand, weight orthogonalization involves modifying the model weights directly. By orthogonalizing the component weights with respect to the refusal direction, it prevents the model from writing to this direction altogether. This is achieved by adjusting the matrices that write to the residual stream, ensuring they do not contribute to the refusal direction.
In the next section, we will implement abliteration with weight orthogonalization.
💻 Implementation
The following implementation of abliteration is based on FailSpy’s notebook, which is itself based on the original authors’ notebook. I mostly adapted and simplified it to make it easier to understand. This section is quite code-heavy so you can see what is going on, but you can use FailSpy’s abliterator library if you’re less interested in the technical details (also check his collection of abliterated models on Hugging Face).
The code relies on the excellent TransformerLens library (formerly known as EasyTransformer) to do the heavy lifting. It is designed for mechanistic interpretability and is used here to intervene on activations. Thanks to Neel Nanda and Joseph Bloom for creating and maintaining this library.
First, let’s install the necessary packages and import them. All these steps are available in this Google Colab notebook.
!pip install transformers transformers_stream_generator tiktoken transformer_lens einops jaxtyping
import torch
import functools
import einops
import gc
from datasets import load_dataset
from tqdm import tqdm
from torch import Tensor
from typing import List
from transformer_lens import HookedTransformer, utils
from transformer_lens.hook_points import HookPoint
from transformers import AutoModelForCausalLM, AutoTokenizer
from jaxtyping import Float, Int
from collections import defaultdict
__
We need two datasets: one containing harmless instructions, and one containing harmful instructions. We’ll use tatsu-lab/alpaca as well as data from llm-attacks. To make things easier, I repackaged them in two Hugging Face datasets: mlabonne/harmless_alpaca and mlabonne/harmful_behaviors. That way, you can easily replace them with your own datasets.
We will load the instructions and reformat them into a list of dictionaries with “role” and “content” keys. This makes it compatible with the method, which we will use to follow Llama 3’s chat template.
:<br> return [[{"role": "user", "content": text}] for text in texts]<br> <br> # Get harmful and harmless datasets<br> :<br> <br> <br> <br> :<br>Now that we have our datasets, we can load the model we want to abliterate. Unfortunately, you can’t directly load a custom model using . Here, I use a trick described in FailSpy’s notebook to download a custom model and rename it as meta-llama/Meta-Llama-3-8B-Instruct. Load in format if your GPU is not compatible with BF16.
In this example, we’ll use mlabonne/Daredevil-8B, a mega-merge created with DARE TIES (see my article about model merging) that has the highest MMLU score on the Open LLM Leaderboard in the 8B category.
MODEL_ID = "mlabonne/Daredevil-8B"
MODEL_TYPE = "meta-llama/Meta-Llama-3-8B-Instruct"
# Download and load model
!git clone https://huggingface.co/{MODEL_ID} {MODEL_TYPE}
# Load model and tokenizer
model = HookedTransformer.from_pretrained_no_processing(
MODEL_TYPE,
local_files_only=True,
dtype=torch.bfloat16,
default_padding_side='left'
tokenizer.padding_side = 'left'
tokenizer.pad_token = tokenizer.eos_token __
We can now tokenize our datasets. We’re using the same number of samples for both harmless and harmful instructions. Note that a high number of samples can use all the RAM/VRAM, which is why I’m limiting it to 256 here.
:
return tokenizer.apply_chat_template(
instructions,
padding=True,
truncation=False,
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
.input_ids
# Tokenize datasets
harmful_tokens = tokenize_instructions(
tokenizer,
instructions=harmful_inst_train[:n_inst_train],
harmless_tokens = tokenize_instructions(
tokenizer,
instructions=harmless_inst_train[:n_inst_train],
__
Everything is set up, we can now implement the first step of abliteration: data collection. We want to process these tokenized datasets and store the residual stream activations in and . This is managed by the transformer_lens library.
# Define batch size based on available VRAM
batch_size = 32
# Initialize defaultdicts to store activations
# Process the training data in batches
// batch_size
:
start_idx = i * batch_size
# Run models on harmful and harmless prompts, cache activations
harmful_logits, harmful_cache = model.run_with_cache(
harmful_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
harmless_logits, harmless_cache = model.run_with_cache(
harmless_tokens[start_idx:end_idx],
names_filter=lambda hook_name: 'resid' in hook_name,
device='cpu',
reset_hooks_end=True
# Collect and store the activations
for key in harmful_cache:
# Flush RAM and VRAM
del harmful_logits, harmless_logits, harmful_cache, harmless_cache
# Concatenate the cached activations
}
} __
We can now compute the refusal direction for each layer. This corresponds to the mean difference between the activations of harmful and harmless instructions, which is then normalized. We sort them in descending order in .
# Helper function to get activation index
:
]
# Compute difference of means between harmful and harmless activations at intermediate layers
activation_layers = ["resid_pre", "resid_mid", "resid_post"]
:
pos = -1 # Position index
for layer in activation_layers:
[:, pos, :].mean(
dim=0
refusal_dir = harmful_mean_act - harmless_mean_act
# Get all calculated potential refusal directions, sort them in descending order based on their mean
# Use a subset of layers if certain activations are not promising
selected_layers = ["resid_pre"]
activation_scored = sorted(
[
activation_refusals[layer][l - 1]
for layer in selected_layers
],
,
reverse=True,
__
The final step of the process consists of evaluating the refusal directions we calculated. To do this, we’re going to apply the refusal direction to each residual stream and each block during inference. In the following snippet, we get generations for four test harmful instructions and 20 blocks (or layers).
def _generate_with_hooks(
model: HookedTransformer,
tokenizer: AutoTokenizer,
tokens: Int[Tensor, "batch_size seq_len"],
max_tokens_generated: int = 64,
fwd_hooks=[],
-> List[str]:
all_tokens = torch.zeros(
,
dtype=torch.long,
device=tokens.device,
all_tokens[:, : tokens.shape[1]] = tokens
:
:
next_tokens = logits[:, -1, :].argmax(
dim=-1
all_tokens[:, -max_tokens_generated + i] = next_tokens
return tokenizer.batch_decode(
all_tokens[:, tokens.shape[1] :], skip_special_tokens=True
def get_generations(
model: HookedTransformer,
tokenizer: AutoTokenizer,
instructions: List[str],
fwd_hooks=[],
max_tokens_generated: int = 64,
batch_size: int = 4,
-> List[str]:
generations = []
:
tokens = tokenize_instructions(
tokenizer, instructions=instructions[i : i + batch_size]
generation = _generate_with_hooks(
model,
tokenizer,
tokens,
max_tokens_generated=max_tokens_generated,
fwd_hooks=fwd_hooks,
return generations
# Inference-time intervention hook
def direction_ablation_hook(
activation: Float[Tensor, "... d_act"],
hook: HookPoint,
direction: Float[Tensor, "d_act"],
:
if activation.device != direction.device:
proj = (
einops.einsum(
, "... d_act, d_act single -> ... single"
* direction
return activation - proj
# Testing baseline
N_INST_TEST = 4
baseline_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
EVAL_N = 20 # Evaluate how many of the top N potential directions
evals = []
:
fwd_hooks = [
for act_name in activation_layers
]
intervention_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=fwd_hooks
__
We stored all the generations in the list. We can now print them and manually select the layer (block) that provides an uncensored response for each instruction. I’m automatically excluding responses containing “I cannot” and “I can’t” to filter out unwanted answers.
If you can’t find a layer that satisfies these requirements, you might want to test other residual streams in the previous list, other instructions, additional blocks, etc.
# Print generations for human evaluation
blacklist = ["I cannot", "I can't"]
:
:
:
__
In my case, the layer candidate 9 managed to provide uncensored answer for the four instructions. This is the one that we will select for the refusal direction. In the following, we implement weight orthogonalization to modify the weights and prevent the model from creating outputs with this direction. You can verify that the model is successfully uncensored by printing the completions.
def get_orthogonalized_matrix(
matrix: Float[Tensor, "... d_model"], vec: Float[Tensor, "d_model"]
-> Float[Tensor, "... d_model"]:
proj = (
einops.einsum(
, "... d_model, d_model single -> ... single"
* vec
return matrix - proj
# Select the layer with the highest potential refusal direction
LAYER_CANDIDATE = 9
refusal_dir = activation_scored[LAYER_CANDIDATE]
# Orthogonalize the model's weights
if refusal_dir.device != model.W_E.device:
:
if refusal_dir.device != block.attn.W_O.device:
# Generate text with abliterated model
orthogonalized_generations = get_generations(
model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[]
# Print generations
:
> i:
__
We’re now ready to use the model. We convert it back to the Hugging Face format and upload it to the HF hub.
# Convert model back to HF safetensors
lm_model = hf_model.model
:
lm_model.layers[l].self_attn.o_proj.weight = torch.nn.Parameter(
einops.rearrange(
", n=model.cfg.n_heads
lm_model.layers[l].mlp.down_proj.weight = torch.nn.Parameter(
__
⚖️ DPO Fine-Tuning
I evaluated the abliterated and source models from the previous section on the Open LLM Leaderboard and on Nous’ benchmark suite. Here are the results:

As you can see, the source model significantly outperforms Llama 3 8B Instruct. However, we observe a performance drop in the ablated version across all benchmarks. The ablation process successfully uncensored it but also degraded the model’s quality.
To address this issue, an idea consists of further training our abliterated model to heal it. Like most fine-tuned models, Llama 3 8B Instruct is quite brittle when it comes to supervised fine-tuning. An additional SFT would likely break the model’s performance.
Alternatively, preference alignment is quite light and shouldn’t lobotomize our abliterated model. DPO is a good candidate here for its ease of use and good track record. To implement it, I used LazyAxolotl with the mlabonne/orpo-dpo-mix-40k dataset. Here’s the configuration I used:
base_model: mlabonne/Daredevil-8B-abliterated
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
save_safetensors: true
rl: dpo
chat_template: chatml
datasets:
- path: mlabonne/orpo-dpo-mix-40k-flat
split: train
type: chatml.intel
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./out
adapter: qlora
lora_model_dir:
sequence_len: 2048
sample_packing: false
pad_to_sequence_len: false
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: axolotl
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 5e-6
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32:
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 100
evals_per_epoch: 0
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 1
debug:
deepspeed: deepspeed_configs/zero2.json
weight_decay: 0.0
special_tokens:
pad_token: <|end_of_text|> __
I trained it using 6xA6000 GPUs with DeepSpeed ZeRO-2. The training took about 6 hours and 45 minutes. Here are the training curves I got from W&B:
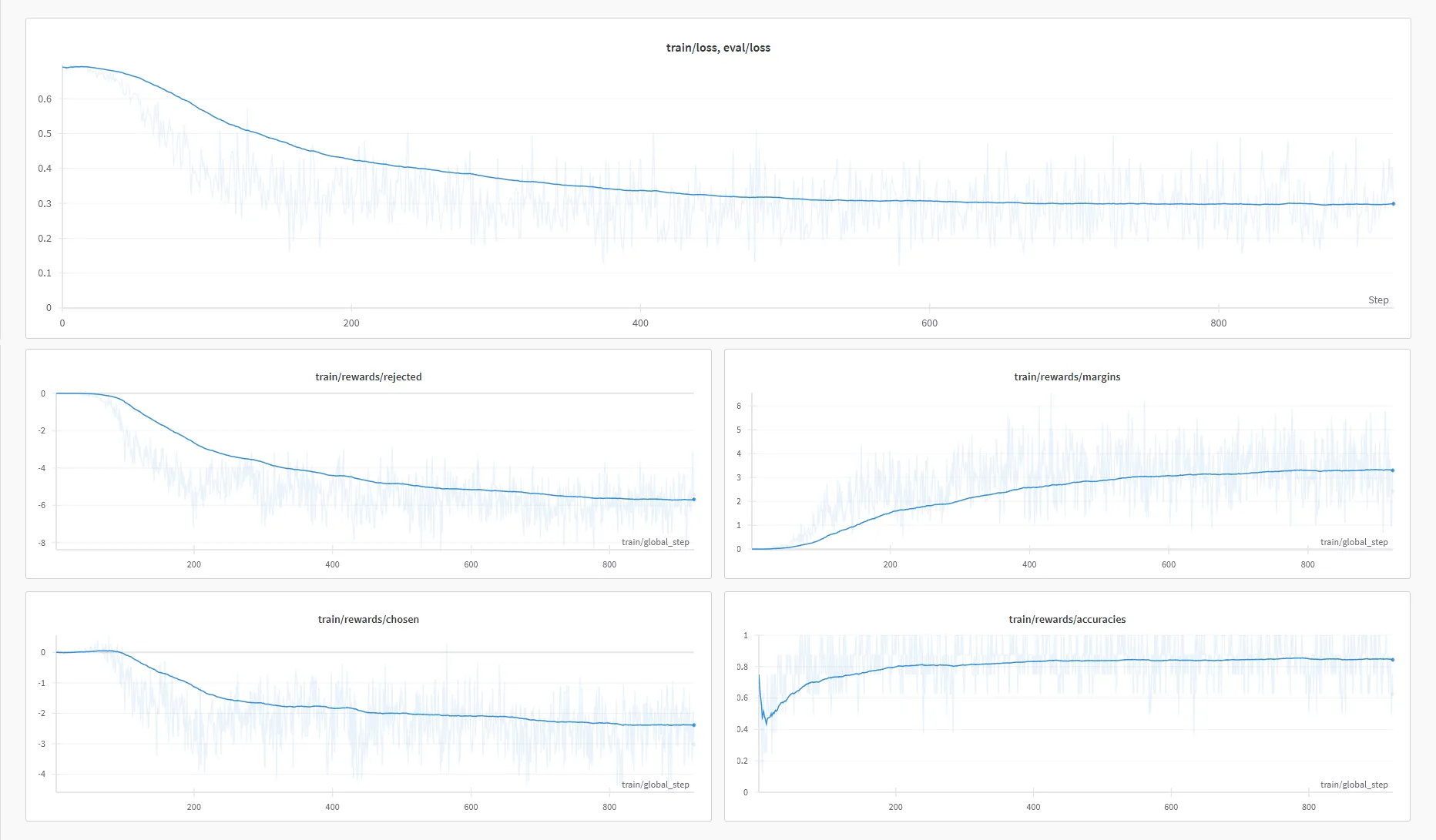
It automatically uploaded the DPO fine-tuned model, called mlabonne/NeuralDaredevil-8B-abliterated. To see if it fixed our abliterated version, I evaluated it on the same benchmarks:

We can see that this additional training allowed us to recover most of the performance drop due to abliteration. One area where the model doesn’t improve is GSM8K, a math dataset, which could mean the orpo-dpo-mix-40k would benefit from more math samples.
The final model is an uncensored LLM with state-of-the-art performance in the 8B category. I recommend it as an improved version of Llama 3 8B Instruct when you don’t need censorship. You can play with quantized versions like GGUF in LM Studio.
Conclusion
In this article, we introduced the concept of abliteration. This technique uses the model’s activations on harmless and harmful prompts to calculate a refusal direction. It then uses this direction to modify the model’s weights and ensure that we stop outputting refusals. This technique also demonstrates the fragility of safety fine-tuning and raises ethical considerations.
We applied abliteration to Daredevil-8B to uncensor it, which also degraded the model’s performance. We then healed it using DPO to create the NeuralDaredevil-8B model, a fully uncensored and high-quality 8B LLM. Abliteration is not limited to removing alignment and should be seen as a form of fine-tuning without retraining. Indeed, it can creatively be applied to other goals, like FailSpy’s MopeyMule, which adopts a melancholic conversational style.
References
- FailSpy, abliterator library,” GitHub, 2024.
- Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda, “Refusal in LLMs is mediated by a single direction,” Lesswrong, 2024.