

What Is Precision?
In machine learning, precision is a model performance metric that corresponds to the fraction of values that actually belong to a positive class out of all of the values which are predicted to belong to that class. Precision is also known as the positive predictive value (PPV).
Equation: Precision = true positives / (predicted true positives + predicted false positives)
Table 1: Confusion Matrix
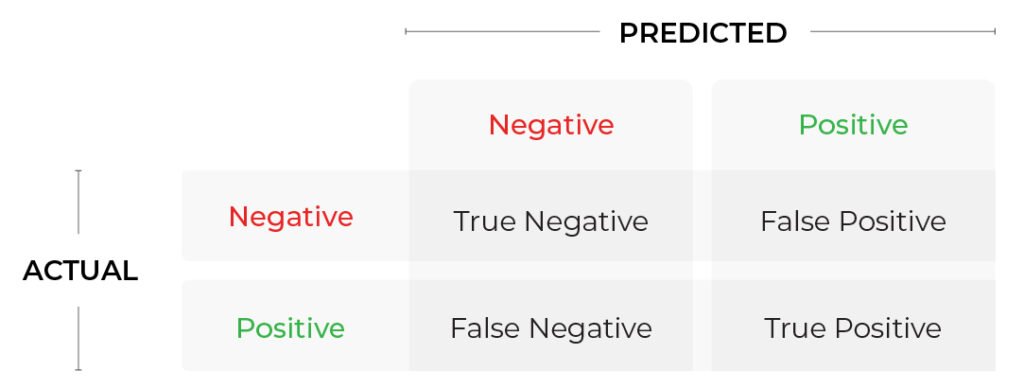
To use an example from the world of credit card fraud models:
- True Positive (TP) = we predict a fraudulent transaction and it was a fraudulent transaction
- True Negative (TN) = we predict a legitimate transaction and it was a legitimate transaction
- False Positive (FP) = we predict a fraudulent transaction and it was a legitimate transaction
- False Negative (FN) = we predict a legitimate transaction and it was a fraudulent transaction
When To Use Precision To Evaluate Performance?
After your machine learning model is put into production, there are several questions to ask yourself before deciding on whether precision is the best performance metric for your use case.
1. What type of model are you using?
If your model is a natural language model or computer vision model, you are likely going to use model specific metrics better designed for unstructured use cases. However, if your model is built on structured data, there will be a different host of potential metrics. For a regression model, you might be more likely to use Mean Square Error (MSE) or Root Mean Square Error (RMSE) or Mean Absolute Error (MAE). For a classification model, metrics like precision, recall, and F1 are the most common evaluation metrics. ****
2. What are you maximizing and what are you minimizing?
As you can see for the equation used to calculate the metric, precision has false positives (FPs) in the denominator – so FPs are important and you want to minimize them. A false positive error is a type I error that predicts a given condition exists when it does not. A simple way to remember when to use precision is thinking about PRE cision in PRE gnancy. If a woman takes a pregnancy test, the worst case scenario would likely be if the test says she is pregnant when she is not. This is a false positive because the woman is wrongly given an affirmative (positive) decision. In this case, you would want to minimize type I errors – a woman thinking they are pregnant when they are not – while maximizing the true positives, or a pregnant woman being informed she is pregnant. Note false negatives (a woman being told she isn’t pregnant when she is) aren’t good either, but they are likely preferable to false positives for the manufacturer of the pregnancy test
3. What are your key performance indicators (KPIs)?
KPIs are related but distinct from evaluation metrics. KPIs take into account the value of the model in terms of how it impacts the bottom line of the company. While metrics like precision and recall give you insights into how the model is doing, KPIs give you insights into how models impact various stakeholders.
For example, let’s say you build a model to predict whether a plane can take off in poor weather. You might use precision and recall to evaluate your model’s performance on historic weather data, but when you consider KPIs that matter to the company – such as net promoter score, customer lifetime value and revenue per customer – the metric you use to make the final decision is critical. In this case, precision might be more important than recall because if you call off a flight due to bad weather then your customers’ satisfaction may go down but the lifetime value is still there.
4. What are the costs to consider?
When you put a machine learning model into production there are various costs to consider, making it important to know:
- Who pays for a negative?
- What is the cost of a positive?
For example, let’s say you have a click through rate model to predict if someone will open an email to register for an event from your company and eventually be converted to a lead. The cost of sending an email is low, so it doesn’t matter if you have some false positives or false negatives because the reward of a true positive is very high. This means precision would be a fine metric to use to evaluate performance.
On the other hand, if your model predicts which event registrants are high-value leads – and therefore should have additional support and resources allocated to them from the team – your cost considerations change. If you are allocating time and resources from your team to pursue a lead and the registrant has no interest in buying, then you are wasting money. At the same time, you need to be sure any registrant who is a potential buyer is given the best experience possible. For this type of cost-benefit relationship, precision is not as important as recall.
When Does Precision Fail?
To recap, precision should be used when you care about how many events are actually positive out of all the predicted positive events. If you care about the positive events that happened which are not predicted (false negatives), however, then precision does not give you the performance insights you need. If you care about minimizing false negatives, you should not use precision.
If you are building a model to predict which patients have cancerous cells, for example, you likely care more about minimizing false negatives than false positives so that a sick person won’t be released and go untreated. Precision overall is a poor metric to use in the field of medical diagnoses for this reason.
What evaluation metric could be used instead of precision?
While there are many metrics to choose from, the F-score is a great option due to it being a measure of the harmonic mean of precision and recall. F-score is a result of integrating these parameters into one for a better understanding of the accuracy of the model. F-score can be modified into F, 0.5, 1, and 2 based on the measure of weightage given to precision over recall. So if precision or recall alone don’t take into account the necessary considerations when evaluating your model – and if you are dealing with a class imbalance – consider the F-score.