

In a remarkably short period of under two months since its initial launch, the ML research group at Apple has made impressive progress with their latest innovation, MLX, as evidenced by its rapid acceptance within the ML community. This is highlighted by its acquisition of more than 12,000 stars on GitHub and the formation of a community surpassing 500 individuals on Hugging Face 🤗.
This investigation aims to assess multiple essential operations that are frequently utilized in neural networks.
Testing Framework
Our evaluation of each operation is based on a series of experiments, varying in input dimensions and magnitude. These were conducted sequentially and multiple times across different processes to guarantee consistent and reliable timing measurements.
With a commitment to open collaboration, we have made the code for the benchmark open-source and straightforward to execute. This initiative allows contributors to easily integrate their own benchmarks based on their hardware and configuration.
Evaluation of Apple’s MLX operations across all Apple Silicon (GPU, CPU) + MPS and CUDA.
Acknowledgment: heartfelt gratitude to all contributors, whose efforts have enriched this benchmark with numerous baseline chips.
We managed to execute this benchmark across 8 distinct Apple Silicon chips and 4 high-efficiency CUDA GPUs:
Apple Silicon: M1, M1 Pro, M2, M2 Pro, M2 Max, M2 Ultra, M3 Pro, M3 Max
CUDA GPU: RTX4090 16GB (Laptop), Tesla V100 32GB (NVLink), Tesla V100 32GB (PCIe), A100 80GB (PCIe).
Results of the Benchmark
For every benchmark, the execution time is recorded in milliseconds. Both MPS and CUDA baselines utilize the operations found within PyTorch, while the Apple Silicon baselines employ operations from MLX.
Linear layer

Image courtesy of the author: Benchmark for the linear operation
- MLX is ~2x quicker than MPS but performs worse on M3* chips
- CUDA GPUs are ~30x quicker than the top-performing M2 Ultra chip Softmax
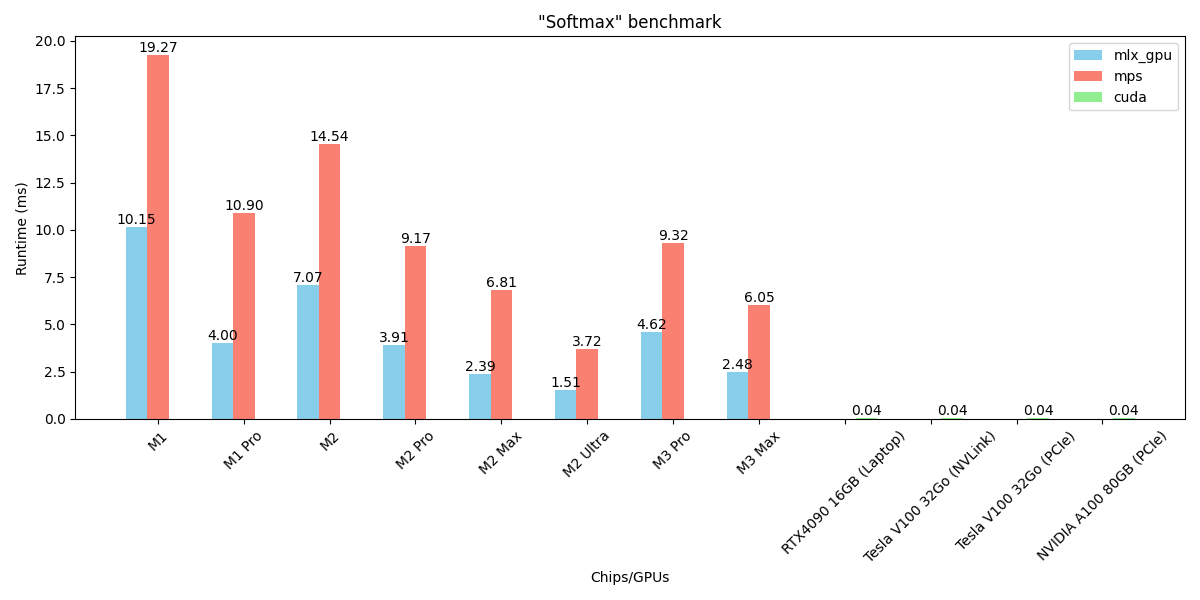
Image courtesy of the author: Benchmark for the softmax operation
- MLX is ~2x quicker than MPS on all chips
- CUDA GPUs are ~30x quicker than M2 Ultra Sigmoid

Image courtesy of the author: Benchmark for the sigmoid operation
- MLX is ~30% quicker than MPS on all chips
- CUDA GPUs are 7x quicker than M2 Ultra Concatenation

Image courtesy of the author: Benchmark for the concatenation operation
- MLX ~30% quicker than MPS on all chips
- CUDA GPUs are ~35x quicker than M2 Ultra Binary Cross Entropy (BCE)
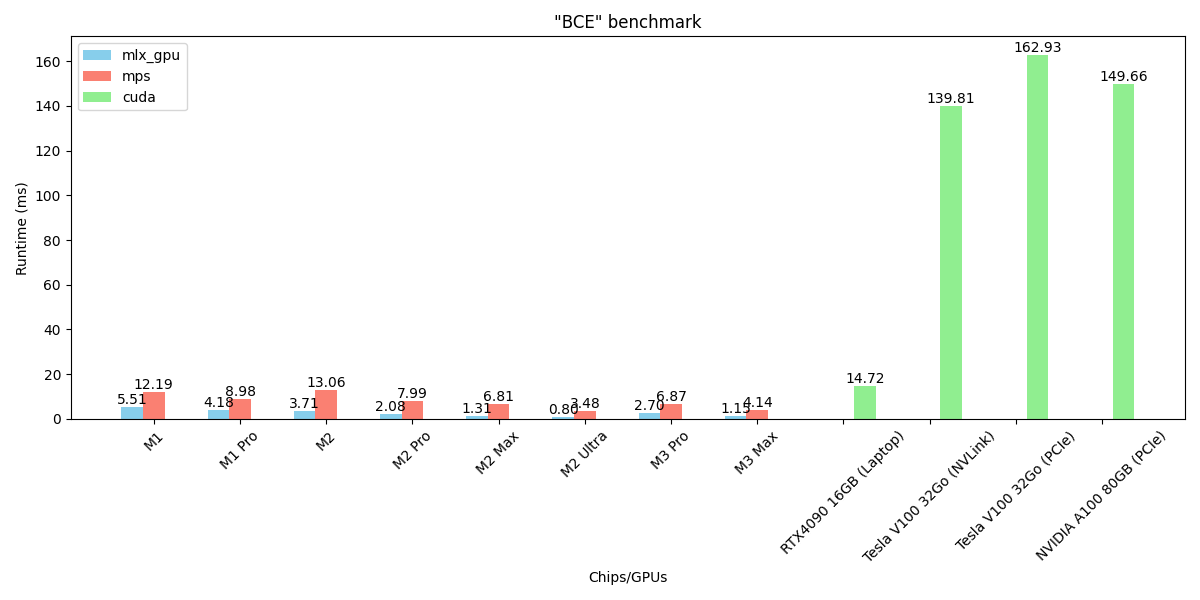
Image courtesy of the author: Benchmark for the BCE operation
- MLX is 2-4x quicker than MPS
- M2 Ultra is ~190x quicker than V100s and A100 GPUs Sort

Image courtesy of the author: Benchmark for the sort operation
- MLX is 3–4x quicker than MPS
- CUDA GPUs are ~20x quicker than M2 Ultra Conv2D

Image courtesy of the author: Benchmark for the Conv2D operation
- MLX is 2–4x slower than MPS
- CUDA GPUs are ~40–300x quicker than MLX
Analysis
Observations
Our benchmarks have led to several key observations:
- MLX operating on Apple Silicon consistently surpasses PyTorch with an MPS backend in the majority of operations.
- CUDA GPUs continue to be significantly faster than Apple Silicon.
- Importantly, MLX shows exceptional performance in certain operations, like Sigmoid and Sort, showcasing impressive efficiency even when compared to CUDA GPU benchmarks.
- The Conv2D operations are still notably slow on MLX. It appears that the MLX team is actively working to enhance the speed of these operations.
Note: For those intrigued, it is recommended to view the 10 additional operations available in the benchmark.
Comparison between Apple Silicon and CUDA GPU
Although CUDA GPUs are unmistakably quicker, it’s vital to consider the bigger context. Nvidia has dedicated years to refining its GPU technology to a point of sophistication and performance that is presently unmatched. Considering the disparity in hardware sophistication, maturity, and expense between Nvidia GPUs and Apple Silicon chips offers a broader perspective.
This is where MLX proves its value. The framework is especially useful for scenarios requiring the operation of large models on personal Macs. MLX enables this without the necessity for additional, costly GPU hardware, marking a significant shift for those seeking efficient machine learning capabilities on Mac devices.
Especially, the recent rise in popularity for running LLM inference directly on Apple Silicon with MLX is noteworthy.
The significance of unified memory
Apple Silicon distinguishes itself in the GPU domain with its unified memory architecture, allowing the use of a Mac’s entire RAM for model execution. This differs significantly from traditional GPU configurations.
Perhaps the most notable benefit of using Apple Silicon is the absence of data transfers between the CPU and GPU. Although it may seem minor, in the realm of machine learning projects, these data transfers are a well-known source of delay.

Image courtesy of the author: Benchmark of GCN with device data transfers
These findings depict the average training duration per epoch for a Graph Convolutional Network model, primarily consisting of two linear layers. Contrasting with the benchmarks in this article, this specific evaluation measures the average runtime for a complete training cycle, inclusive of the time for data transfers from CPU to GPU.
An intriguing insight emerges from these results: the performance of CUDA GPUs significantly diminishes when actual data transfer times are factored in. This emphasizes the substantial impact that data transfers have on overall speed, a factor that cannot be ignored in the current benchmark.
Conclusion
This benchmark provides a transparent view of MLX’s performance in comparison to PyTorch running on MPS and CUDA GPUs. We discovered that MLX is generally much faster than MPS for most operations but also slower than CUDA GPUs.
MLX’s standout feature is its unified memory, which negates the need for the time-consuming data transfers between the CPU and GPU.