
Latest Posts
-
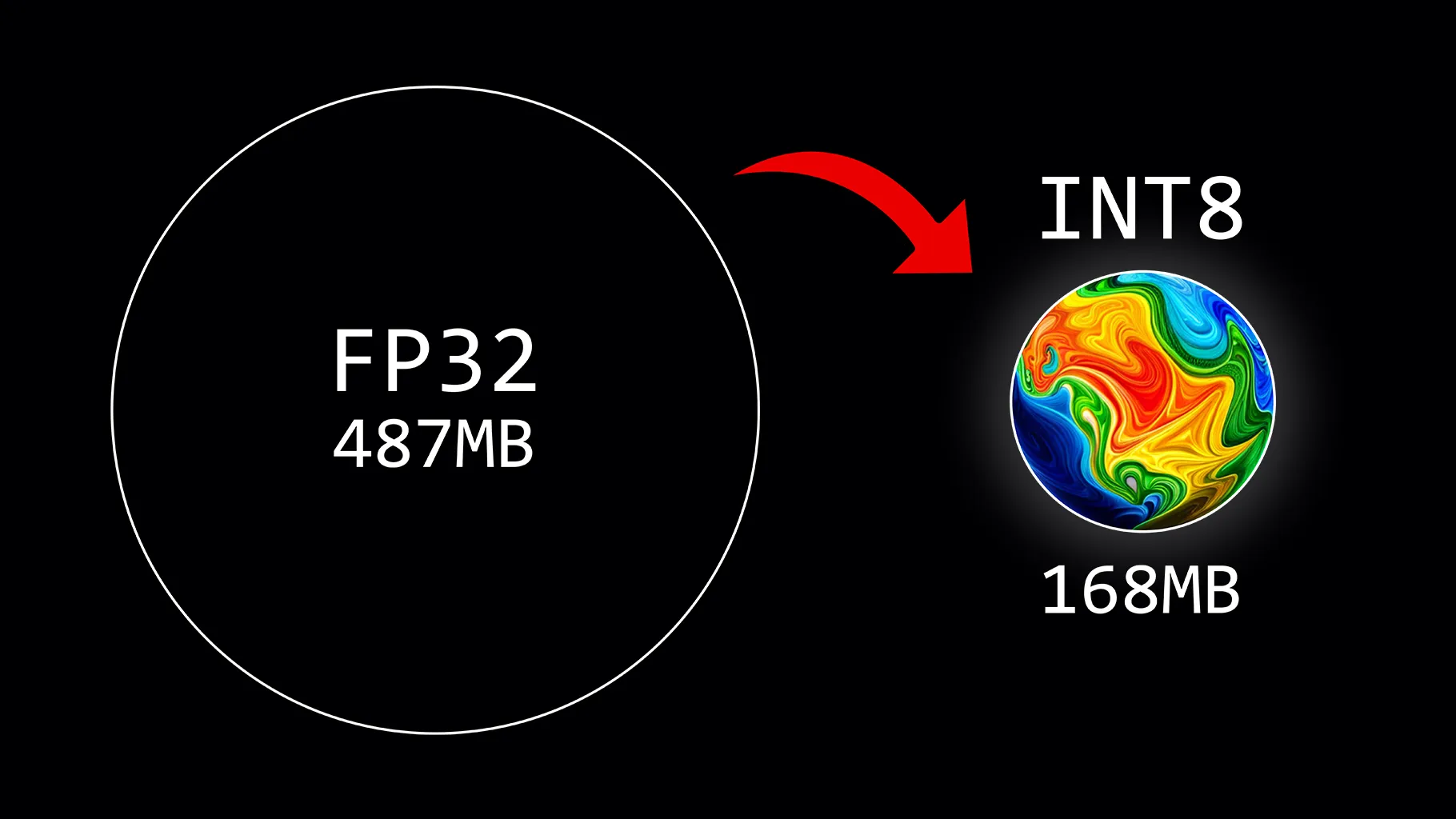
·
Introduction to Weight Quantization
Large Language Models (LLMs) are known for their extensive computational requirements. Typically, the size of a model is calculated by multiplying the number of parameters ( size ) by the precision of these values ( data type ). However, to save memory, weights can be stored using lower-precision data types through a process known as…
-

·
Step-by-step guide to supervised fine-tune Llama 2 in Google Colab.
With the release of LLaMA v1, we saw a Cambrian explosion of fine-tuned models, including Alpaca, Vicuna, WizardLM, among others. This trend encouraged different businesses to launch their own base models with licenses suitable for commercial use, such as OpenLLaMA, Falcon, XGen, etc. The release of Llama 2 now combines the best elements from both…
-
·
End-to-end guide to the state-of-the-art tool for fine-tuning.
The growing interest in Large Language Models (LLMs) has led to a surge in tools and wrappers designed to streamline their training process. Popular options include FastChat from LMSYS (used to train Vicuna) and Hugging Face’s transformers/trl libraries (used in my previous article). In addition, each big LLM project, like WizardLM, tends to have its…
-

·
Boost the performance of supervised fine-tuned models with DPO.
Pre-trained Large Language Models (LLMs) can only perform next-token prediction, making them unable to answer questions. This is why these base models are then fine-tuned on pairs of instructions and answers to act as helpful assistants. However, this process can still be flawed: fine-tuned LLMs can be biased, toxic, harmful, etc. This is where Reinforcement…
-
·
Fine-tune Llama 3 with ORPO
ORPO is a new exciting fine-tuning technique that combines the traditional supervised fine-tuning and preference alignment stages into a single process. This reduces the computational resources and time required for training. Moreover, empirical results demonstrate that ORPO outperforms other alignment methods on various model sizes and benchmarks. In this article, we will fine-tune the new…
-

·
Fine-tune Llama 3.1 Ultra-Efficiently with Unsloth
A beginner’s guide to state-of-the-art supervised fine-tuning The recent release of Llama 3.1 offers models with an incredible level of performance, closing the gap between closed-source and open-weight models. Instead of using frozen, general-purpose LLMs like GPT-4o and Claude 3.5, you can fine-tune Llama 3.1 for your specific use cases to achieve better performance and…
-

·
Transformer squared: Self-Adaptive LLMs
Intro Adaptation is one of the most remarkable phenomena in nature. From the way an octopus can change their skin color to blend into its surroundings, to how the human brain rewires itself after an injury, allowing individuals to recover lost functions and adapt to new ways of thinking or moving. Living organisms exhibit adaptability…
-

·
Scaling AI in the Classroom: A Khan Academy Case Study with Khanmigo
Khan Academy’s mission is to provide free, world-class education to everyone, everywhere. This blog post explores Khanmigo, our AI tutor and teacher assistant, and how it helps us achieve this mission at scale. We’ll delve into the problems we’re tackling, our solutions, technical challenges, and future plans. The Challenge: Bridging the Widening Learning Gap The…
-
·
From DevOps to AIOps: Building a Scalable AI Platform
The evolution of software development has seen a constant influx of new paradigms. From Agile to DevOps, each shift has aimed to optimize processes and enhance collaboration. Today, Artificial Intelligence (AI) stands as the next transformative force. This blog post explores the journey from DevOps to AIOps, emphasizing the importance of a robust AI platform…