

Abacus.ai has introduced Smaug, an enhanced iteration of Qwen_72B by Alibaba, which unarguably stands as the new sovereign of open-source, being the inaugural open-source model to ever achieve an average score of 80 across various benchmarks.
Additionally, it stands as irrefutable evidence that we have at last discovered a definitive method that narrows the divide between open-source and proprietary models, DPO, which we discussed in my newsletter __ a couple of weeks back.
Let’s delve into the mysteries of the new monarch beneath the mountain.
A Masterpiece
In the first place, you need not take just my assertion for it being the premier open-source model, as it is already recognized as such on the renowned Open LLM leaderboard from HuggingFace.
And though Alibaba is the issuer of the license (it’s not a completely open license like Apache 2.0) it’s quite liberal, indicating you only need to seek permission for its commercial use if your product garners more than 100 million users.
That’s a stipulation I believe you’ll find agreeable.
So, what exactly is Smaug?
Smaug represents an optimized, DPO-conformant version of Qwen-72B, an exceptional Large Language Model (LLM) from Alibaba that draws significant influence from Meta’s LLaMa 2 model.
As you might already be aware, LLaMa embodies a lineage of pre-trained generative transformers (akin to GPT for OpenAI or Gemini for Google) which are universally regarded as the top open-source foundational models in the sector.
Indeed, they are the foundational model that underpins most open-source models currently.
Furthermore, as Mark Zuckerberg himself has stated, they are in the process of developing version 3.0, suggesting we might be mere weeks from the next significant advancement in open-source capabilities.
In the interim, nothing surpasses Smaug in the realm of open-source, and incredibly, it even outperforms some of the leading proprietary models globally, including Google’s Gemini 1.0 Pro in certain benchmarks (not to be confused with the more recent version unveiled a few days prior) and Mistral-Medium from Mistral, according to Abacus AI’s founder, Bingu Reddy.
Should these assertions prove accurate on a large scale, it would place Smaug among the top-5 foundational models globally, ranking it nearly on par with GPT-4 and Gemini Ultra despite being over ten times less sizable!
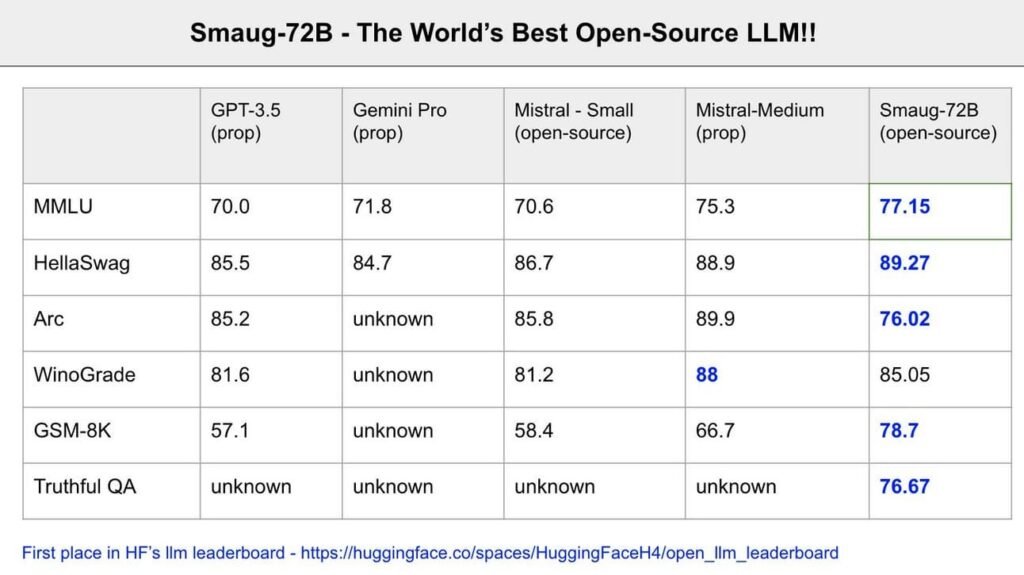
** What do these benchmarks entail?**
Winograd : Evaluates AI’s grasp of language ambiguity necessitating common sense.
TruthfulQA : Tests AI’s capacity to offer precise and truthful responses.
GSM-8k : Puts AI to the test with elementary school level arithmetic queries.
ARC : Gauges AI’s reasoning across intricate, knowledge-dense questions.
HellaSwag : Assesses AI’s ability to forecast logical scenario conclusions employing commonsense reasoning.
MMLU : Probes AI’s comprehension over a broad array of subjects and tasks.
But how has this been achieved? What’s behind such significant enhancements in open-source models?
And the response might indeed be, DPO.
The Alignment Milestone
Merely a few months back, the prevailing belief was that these models and their inductive biases (the presumptions these models employ when processing new data to yield accurate predictions) were somewhat lacking, thus necessitating substantial human intervention.
Yet, it has been discovered that aligning models (optimizing their utility and safety for use) is a task far simpler than previously imagined.
Termed Direct Preference Optimization by Rafailov and colleagues, it has emerged as the definitive strategy for model alignment, with recent instances including Mixtral 8×7B and Smaug.
In simpler terms, whereas the traditional method known as Reinforcement Learning from Human Feedback, or RLHF, required developing a separate reward model — the instructor — to guide our model in ‘appropriate behavior’, it has been realized that, akin to humans, models are capable of self-instruction.
How is DPO implemented?
The final stage of LLM training, the alignment phase, aids the models in developing a decision-making policy that enhances action choices by maximizing a human-derived score.
The innovation of DPO lies in identifying this policy for decision-making without the necessity of score calculation, rendering the process both faster and less costly compared to traditional methods.
To put it another way, it’s analogous to educating a pupil in mathematics, but rather than subjecting him/her to numerous quizzes and requiring a teacher to score these, and repeating this cycle until a perfect score is achieved, you impart the fundamental concepts that inherently equip the student with the ability to self-educate and excel without undergoing countless evaluations.
Naturally, just as hiring a teacher is significantly more costly than enabling a student to self-educate, DPO demands far fewer resources, allowing researchers to extend training durations and use more data, thereby enhancing model quality.
For more detailed insights, you can read here my detailed discussion on what DPO and RLHF entail. For a practical demonstration, I highly recommend this recent AI tutorial by HuggingFace and DeepLearning.ai
“My suit acts as shields multiplied by ten, my fangs are as blades, my talons like lances, the impact of my tail equals a lightning strike, my pinions a tempest, and my exhalation is demise!”
Such were the declarations of the principal villain in one of The Hobbit movies, the immense wyrm that nearly ended the life of our beloved protagonist Bilbo, instilling terror in his heart.
Now, a similar sensation may have been experienced by the open-source community as Abacus.ai has introduced Smaug, an enhanced iteration of Qwen_72B by Alibaba, which unarguably stands as the new sovereign of open-source, being the inaugural open-source model to ever achieve an average score of 80 across various benchmarks.
Additionally, it stands as irrefutable evidence that we have at last discovered a definitive method that narrows the divide between open-source and proprietary models, DPO, which we discussed in my newsletter __ a couple of weeks back.
Let’s delve into the mysteries of the new monarch beneath the mountain.
A Masterpiece
In the first place, you need not take just my assertion for it being the premier open-source model, as it is already recognized as such on the renowned Open LLM leaderboard from HuggingFace.
And though Alibaba is the issuer of the license (it’s not a completely open license like Apache 2.0) it’s quite liberal, indicating you only need to seek permission for its commercial use if your product garners more than 100 million users.
That’s a stipulation I believe you’ll find agreeable.
So, what exactly is Smaug?
Smaug represents an optimized, DPO-conformant version of Qwen-72B, an exceptional Large Language Model (LLM) from Alibaba that draws significant influence from Meta’s LLaMa 2 model.
As you might already be aware, LLaMa embodies a lineage of pre-trained generative transformers (akin to GPT for OpenAI or Gemini for Google) which are universally regarded as the top open-source foundational models in the sector.
Indeed, they are the foundational model that underpins most open-source models currently.
Furthermore, as Mark Zuckerberg himself has stated, they are in the process of developing version 3.0, suggesting we might be mere weeks from the next significant advancement in open-source capabilities.
In the interim, nothing surpasses Smaug in the realm of open-source, and incredibly, it even outperforms some of the leading proprietary models globally, including Google’s Gemini 1.0 Pro in certain benchmarks (not to be confused with the more recent version unveiled a few days prior) and Mistral-Medium from Mistral, according to Abacus AI’s founder, Bingu Reddy.
Should these assertions prove accurate on a large scale, it would place Smaug among the top-5 foundational models globally, ranking it nearly on par with GPT-4 and Gemini Ultra despite being over ten times less sizable!
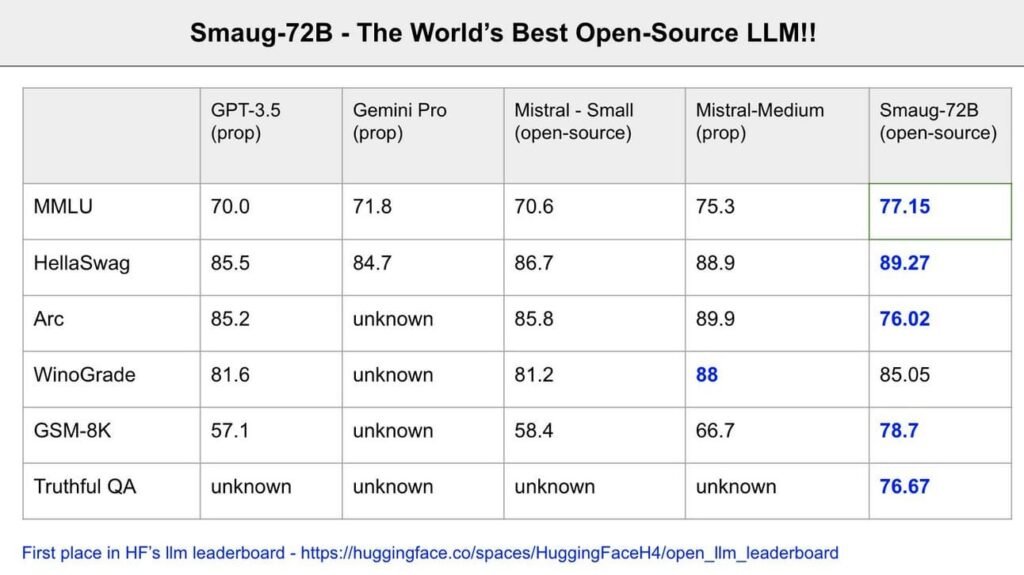
** What do these benchmarks entail?**
Winograd : Evaluates AI’s grasp of language ambiguity necessitating common sense.
TruthfulQA : Tests AI’s capacity to offer precise and truthful responses.
GSM-8k : Puts AI to the test with elementary school level arithmetic queries.
ARC : Gauges AI’s reasoning across intricate, knowledge-dense questions.
HellaSwag : Assesses AI’s ability to forecast logical scenario conclusions employing commonsense reasoning.
MMLU : Probes AI’s comprehension over a broad array of subjects and tasks.
But how has this been achieved? What’s behind such significant enhancements in open-source models?
And the response might indeed be, DPO.
The Alignment Milestone
Merely a few months back, the prevailing belief was that these models and their inductive biases (the presumptions these models employ when processing new data to yield accurate predictions) were somewhat lacking, thus necessitating substantial human intervention.
Yet, it has been discovered that aligning models (optimizing their utility and safety for use) is a task far simpler than previously imagined.
Termed Direct Preference Optimization by Rafailov and colleagues, it has emerged as the definitive strategy for model alignment, with recent instances including Mixtral 8×7B and Smaug.
In simpler terms, whereas the traditional method known as Reinforcement Learning from Human Feedback, or RLHF, required developing a separate reward model — the instructor — to guide our model in ‘appropriate behavior’, it has been realized that, akin to humans, models are capable of self-instruction.
How is DPO implemented?
The final stage of LLM training, the alignment phase, aids the models in developing a decision-making policy that enhances action choices by maximizing a human-derived score.
The innovation of DPO lies in identifying this policy for decision-making without the necessity of score calculation, rendering the process both faster and less costly compared to traditional methods.
To put it another way, it’s analogous to educating a pupil in mathematics, but rather than subjecting him/her to numerous quizzes and requiring a teacher to score these, and repeating this cycle until a perfect score is achieved, you impart the fundamental concepts that inherently equip the student with the ability to self-educate and excel without undergoing countless evaluations.
Naturally, just as hiring a teacher is significantly more costly than enabling a student to self-educate, DPO demands far fewer resources, allowing researchers to extend training durations and use more data, thereby enhancing model quality.
A Narrowing Gap for OpenAI
As I mentioned when initially discussing this subject, Smaug merely validates that the most substantial competitive advantage held by closed-source models, the highly capital-intensive alignment phase, has now been eliminated.
And while many are focused on the fact that it’s the first open-source model to achieve an average of 80 across well-known benchmarks, it signifies much more.
It evidences that DPO is a genuine breakthrough , heralding an era of super-powerful open-source models on the horizon.
In essence, unless OpenAI and similar entities unveil a novel technological advancement, their competitive edge in the realm of LLMs is gradually but inexorably diminishing.
To read more summary like this checkout this page