
Latest Posts
-

·
The full training run of GPT-5 has gone live
We can expect it to be released in November, maybe on the 2nd anniversary of the legendary ChatGPT launch In similar timeframes, we will also be getting Gemini 2 Ultra, LLaMA-3, Claude-3, Mistral-2 and many other groundbreaking models (Google’s Gemini already seems to be giving tough competition to GPT-4 turbo) It is almost certain that…
-

·
7 Books to Read on Artificial Intelligence
2024 is thought to be the “year of AI”, where we will see even more breakthroughs than in 2023. In this post I will share some of the most interesting books about Artificial Intelligence I have been reading lately, together with my own thoughts: Life 3.0 Image by author. In this book, Tegmark talks about…
-

·
Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters
In the rapidly evolving field of artificial intelligence, utilizing large language models in an efficient and effective manner has become increasingly important. Parameter-efficient finetuning stands at the forefront of this pursuit, allowing researchers and practitioners to reuse pretrained models while minimizing their computational and resource footprints. It also allows us to train AI models on…
-

·
Some Techniques To Make Your PyTorch Models Train (Much) Faster
This blog post outlines techniques for improving the training performance of your PyTorch model without compromising its accuracy. To do so, we will wrap a PyTorch model in a LightningModule and use the Trainer class to enable various training optimizations. By changing only a few lines of code, we can reduce the training time on…
-

·
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of techniques that can lower memory consumption by approximately 20x without sacrificing modeling performance and prediction accuracy. Introduction In this article, we will be exploring 9 easily-accessible techniques to reduce memory usage…
-

·
Improving LoRA: Implementing DoRA from Scratch
Low-rank adaptation (LoRA) is a machine learning technique that modifies a pretrained model (for example, an LLM or vision transformer) to better suit a specific, often smaller, dataset by adjusting only a small, low-rank subset of the model’s parameters. This approach is important because it allows for efficient finetuning of large models on task-specific data,…
-

·
Finetuning Falcon LLMs More Efficiently With LoRA and Adapters
Finetuning allows us to adapt pretrained LLMs in a cost-efficient manner. But which method should we use? This article compares different parameter-efficient finetuning methods for the latest top-performing open-source LLM, Falcon. Using parameter-efficient finetuning methods outlined in this article, it’s possible to finetune an LLM in 1 hour on a single GPU instead of a…
-

·
How to Fine-Tune LLMs with Hugging Face
Large Language Models or LLMs have seen a lot of progress in the last year. We went from no ChatGPT competitor to a whole zoo of LLMs, including Meta AI’s Llama 2, Mistrals Mistral & Mixtral models, TII Falcon, and many more. Those LLMs can be used for a variety of tasks, including chatbots, question…
-
·
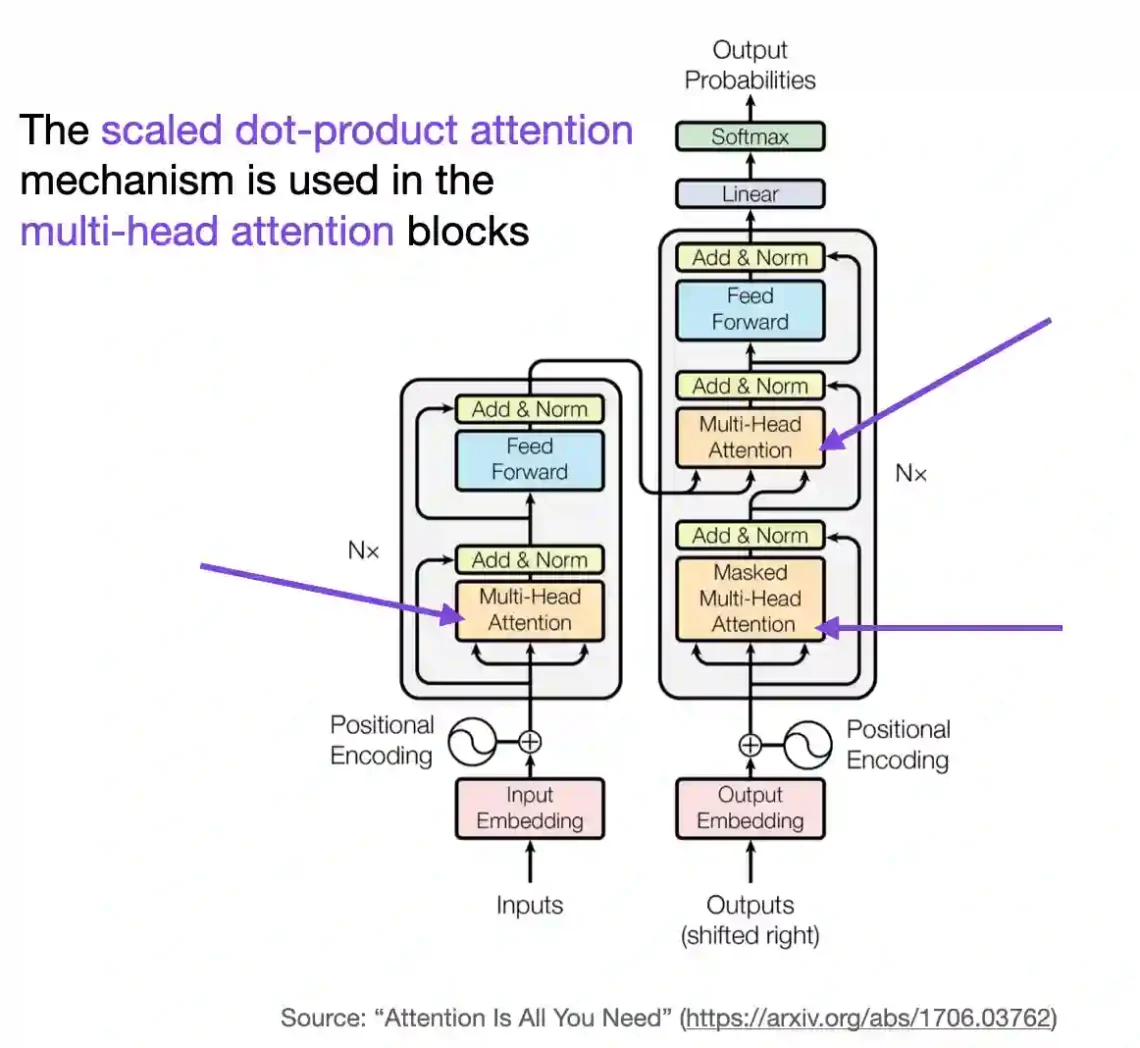
Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
In this article, we are going to understand how self-attention works from scratch. This means we will code it ourselves one step at a time. Since its introduction via the original transformer paper (Attention Is All You Need), self-attention has become a cornerstone of many state-of-the-art deep learning models, particularly in the field of Natural…