

LLaMA is a collection of foundation language models ranging from 7B to 65B parameters, trained on trillions of tokens using publicly available datasets exclusively.
Training Data
English CommonCrawl [67%]
Five CommonCrawl dumps, ranging from 2017 to 2020, are preprocessed using the CCNet pipeline. This process deduplicates the data at the line level, performs language identification with a fastText linear classifier to remove non-English pages, and filters low-quality content with an ngram language model. Furthermore, a linear model is trained to classify pages as references in Wikipedia versus randomly sampled pages, and pages not classified as references are discarded.
C4 [15%]
During exploratory experiments, it was observed that performance is improved by using diverse pre-processed CommonCrawl datasets. Thus, the publicly available C4 dataset was included in the data. The preprocessing of C4 also includes deduplication and language identification steps: the main difference with CCNet is the quality filtering, which is mostly based on heuristics such as the presence of punctuation marks or the number of words and sentences in a webpage.
GitHub [4.5%]
The public GitHub dataset available on Google BigQuery is utilized. Only those projects that are distributed under the Apache, BSD, and MIT licenses have been retained by us. Furthermore, heuristics based on line length or the proportion of alphanumeric characters have been applied to filter out low-quality files. Boilerplate content, such as headers, has also been removed by us using regular expressions. Finally, the resulting dataset is deduplicated at the file level through exact matches.
Wikipedia [4.5%]
Wikipedia dumps from the June-August 2022 period, covering 20 languages that use either the Latin or Cyrillic scripts (bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk), have been added. The data is then processed to remove hyperlinks, comments, and other formatting boilerplate.
Gutenberg and Books3 [4.5%]
Two book corpora are included in our training dataset: the Gutenberg Project, which contains books that are in the public domain, and the Books3 section of ThePile, a publicly available dataset for training large language models. Deduplication is performed at the book level, with books having more than 90% content overlap being removed.
ArXiv [2.5%]
ArXiv Latex files are processed to include scientific data in the dataset. Everything before the first section is removed, along with the bibliography. Comments from the .tex files are also removed, and definitions and macros written by users are inline-expanded by us to increase consistency across papers.
Stack Exchange [2%]
A dump of Stack Exchange, a website containing high-quality questions and answers covering a diverse range of domains, from computer science to chemistry, has been included by us. The data from the 28 largest websites was retained, HTML tags were removed from the text, and the answers were sorted by score, from highest to lowest.

Pre-training data. Data mixtures used for pretraining.
Tokenizer
The data is tokenized using the bytepair encoding (BPE) algorithm. Notably, all numbers are split into individual digits and fall back to bytes to decompose unknown UTF-8 characters.
Overall, the entire training dataset contains roughly 1.4T tokens after tokenization. For most of the training data, each token is used only once during training, with the exception of the Wikipedia and Books domains, over which perform approximately two epochs.
Architecture
The network is based on the transformer architecture. Various improvements that were subsequently proposed and used in different models are leveraged.
Pre-normalization [GPT3]
To improve training stability, the input of each transformer sub-layer is normalized (using RMSNorm) instead of normalizing the output.
SwiGLU activation function [PaLM]
The ReLU non-linearity is replaced by the SwiGLU activation function with a dimension of 2/3 4d instead of 4d as in PaLM.
Rotary Embeddings [GPTNeo]
Rotary positional embeddings (RoPE) are used instead of absolute positional embeddings, at each layer of the network.
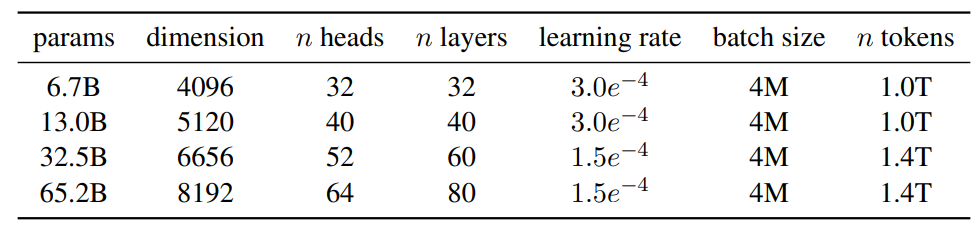
Model sizes, architectures, and optimization hyper-parameters.
Results
LLaMa considers zero-shot and few-shot tasks, and reports results on a total of 20 benchmarks:
- Zero-shot: A textual description of the task and a test example are provided by us. An answer is either generated using open-ended generation by the model or the proposed answers are ranked.
- Few-shot: A few examples of the task (between 1 and 64) and a test example are provided. This text is taken as input by the model, and the answer or different options are generated by it.
Common Sense Reasoning
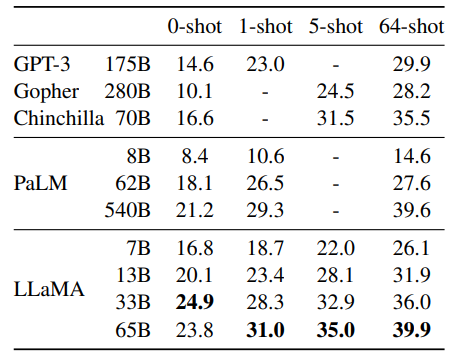
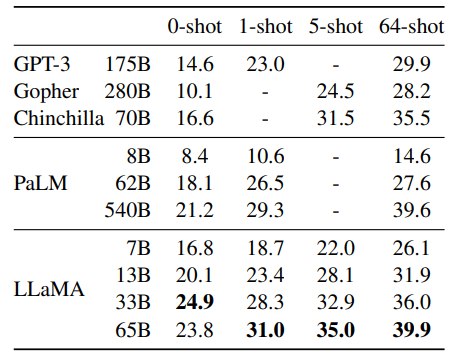
Zero-shot performance on Common Sense Reasoning tasks.
- LLaMA-65B outperforms Chinchilla-70B on all benchmarks except BoolQ.
- LLaMA-65B also surpasses PaLM540B everywhere except BoolQ and WinoGrande.
- LLaMA-13B outperforms GPT-3 on most benchmarks despite being much smaller.
Closed-book Question Answering
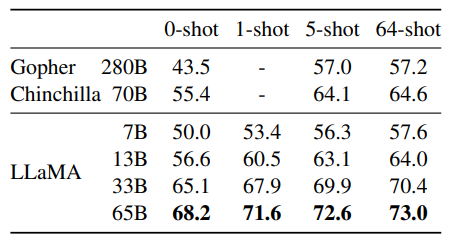
NaturalQuestions. Exact match performance
TriviaQA. Zero-shot and few-shot exact match performance on the filtered dev set.
- LLaMA-65B achieves state-of-the-art performance in the zero-shot and few-shot settings on both benchmarks.
- LLaMA-13B is competitive with GPT-3 and Chinchilla on these benchmarks despite being 5–10 times smaller.
Reading Comprehension
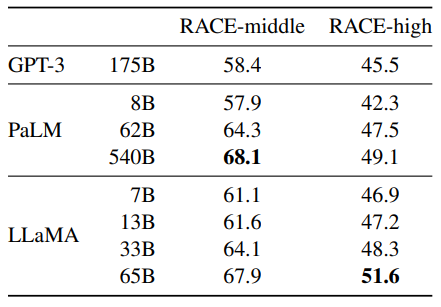
Reading Comprehension. Zero-shot accuracy.
- Competitive performance of LLaMA-65B with PaLM-540B.
- LLaMA-13B outperforms GPT-3 by a few percentage points.
Mathematical reasoning
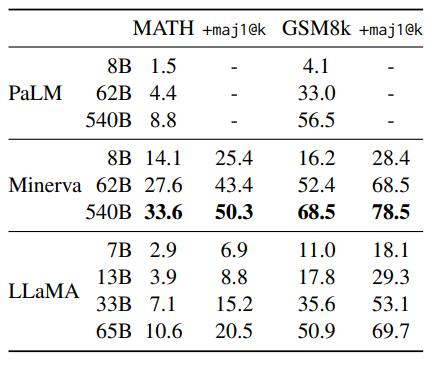
Model performance on quantitative reasoning datasets.
- Minerva is a series of PaLM models fine-tuned on 38.5B tokens from ArXiv and Math Web Pages.
- PaLM and LLaMA models are not fine-tuned on mathematical data.
- Results compared with and without maj1@k, which involves generating k samples for each problem and performing majority voting.
- LLaMA65B outperforms Minerva-62B on GSM8k, even though it’s not fine-tuned on mathematical data.
Code generation
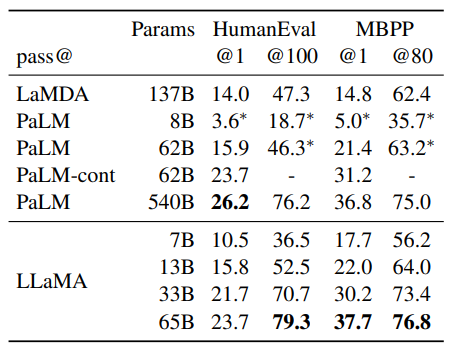
Model performance for code generation.
- LLaMA 13B performs better than LaMDA 137B on both HumanEval and MBPP.
- LLaMA 65B outperforms PaLM 62B, even with longer training.
- Models trained specifically for code perform better than general models on these tasks. However, fine-tuning on code tokens is not the focus of this paper.
Massive Multitask Language Understanding
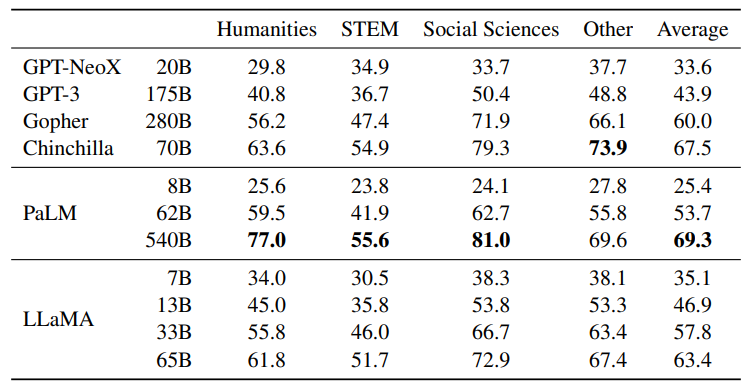
Massive Multitask Language Understanding (MMLU). Five-shot accuracy.
- LLaMA-65B lags behind Chinchilla70B and PaLM-540B in performance on the MMLU benchmark.
- The possible reason for the performance gap is the smaller amount of pre-training data (177GB) used for LLaMA-65B compared to Gopher, Chinchilla, and PaLM models (up to 2TB of books).
- The larger quantity of books in the training data may explain why Gopher outperforms GPT-3 specifically on the MMLU benchmark.
Instruction Finetuning
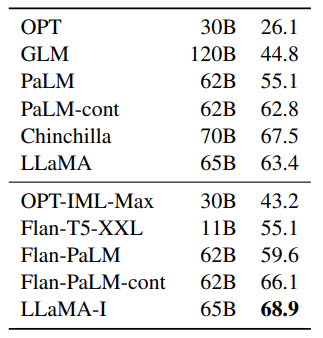
Instruction finetuning — MMLU (5-shot). Comparison of models of moderate size with and without instruction finetuning on MMLU
- Even without fine-tuning, LLaMA-65B can follow basic instructions.
- LLaMA-I (65B) achieves 68.9% on MMLU, outperforming other moderate-sized instruction fine-tuned models.
- However, it still falls short of the state-of-the-art, which is 77.4 for GPT code-davinci-002 on MMLU.
Paper
LLaMA: Open and Efficient Foundation Language Models 2302.13971